最重要技術の深層学習は半導体が支える
人間の脳は、10年や100年で大きく仕組みが変化することはない。しかし、現在の人工知能は、まさに日進月歩である。より複雑な対象の認知、適用範囲の拡大、使い勝手が向上し続けている。ここからは、人工知能の進化の方向性についてみてみよう。
機械学習を基にした人工知能を社会で活用する上で、今、その技術開発の中心軸となっている技術が、「深層学習(ディープラーニング)」と呼ばれる技術である。パターン認識、特に画像認識や言語処理の性能向上に、圧倒的な威力を発揮している。深層学習は、脳の構造を工学的に再現した「ニューラルネットワーク」と呼ばれる神経回路網のモデルを用いた機械学習の手法である(図3)。基本的にどのような作業でも学習できる。これからの発展が期待されているIoTシステムも自動運転も、ロボットによる作業も、その進化の鍵は深層学習の高度化にある。
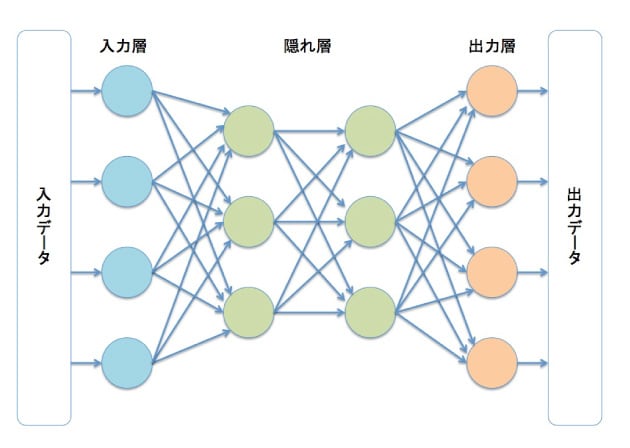 |
ニューラルネットワークは、データを受け取る入力層、学習内容に応じてネットワークの状態を変える隠れ層、データを吐き出す出力層の3つの部分で構成されている。神経細胞の働きを模したニューロン(図3の丸の部分)では、前の層のすべてのニューロンの出力を受け取り、それらにそれぞれ異なる"重み値(ウエイト)*5"を乗じて合算する。その合計値にシステム設計者が定めた計算を施し、結果が一定以上になれば、そのニューロンが有効な状態("発火"と呼ぶ)になる。
ニューラルネットワーク(図3)での学習とは、思い通りの出力に近づくように、"重み値"を少しずつ調整・更新する作業のことを指す。どのような学習をするときに、どの程度"重み値"を変えるのかといったさじ加減が、人工知能システムを設計するエンジニアの腕の見せ所である。また、深層学習では、隠れ層の部分を20層~30層と深くしニューロンの数を増やすことにより、より確度の高い判断ができるようになる。現在では、画像認識に応用すると人間とほぼ同じ約95%の正解率で応えられるまでに進化している。
深層学習を用いて、大量の訓練データを学習するためには、強力な計算能力が必要になる。ニューラルネットワークを基にしたパターン認識のアイデアは過去にもあったが、学習時間が掛かり過ぎて使いものにならなかった。しかし、パワフルな半導体、特にパソコンなどに搭載されているグラフィックスチップ(GPU)*6が学習に利用できるようになり、一気に実用に向かった。ニューロン数を100万個ほどに大規模化した場合でも、数時間〜数日で学習を終えられるようになった。
課題先進国である日本のデータがお宝に
深層学習をはじめとする人工知能の機械学習の学習法には、2つの方法がある。入力データと出力データの関係を人間が教えて学習させる「教師あり学習」と、入力データだけを用いて、システム自身が傾向を導き出したり、多数のデータを少ないデータにまとめ上げたりする「教師なし学習」である。
「教師あり学習」は、画像や音声の認識などの分野で成果を上げている。入出力の関係を示した大量の訓練データさえ用意すれば、数値やテキストなど、どのような情報の相互関係もニューラルネットワークにすり込むことができる。ただし、教師が訓練データを作成するのに大きなコストが掛かるのが難点である。前述した犬を見分ける問題では、人間が写真を見て、一つずつ判断して正解を打ち込む必要がある。これは知的作業や先端技術とはほど遠い、単純な人海戦術になる。
さらに、質の高い訓練データを、どれだけ用意できるかも重要になる。これから社会が解決していくべき問題の解決や、消費者が便利だと考えるサービスの提供を、先回りして人工知能に教え込む必要がある。こうした訓練データの質という点では、世界に先駆けて少子高齢化やエネルギー問題など数々の社会問題に直面する日本には、全世界垂涎のデータがあるように思える。
一方、教師なし学習は、学習コストが安くすむ利点がある。世界中のウエブサイトにあるテキストや画像などを訓練データとして使うことができるからだ。ただし、正解が分からなくても実現できる作業だけにしか適用できない。例えば、よく似た画像をグループ分けするといった作業である。グループ分けを進めた後に、人間が各グループに「これは犬の写真である」といった意味付けをしたり、「教師あり学習」と組み合わせたりして使う。
時間の流れを感じて未来を予測する技術
「教師あり学習」は、さらに適用範囲を拡大する方向に進化している。これまで一度学習を終えた人工知能は、新たな学習をしない限り、同じ入力を与えれば常に同じ出力を出していた。一度、「犬が写っている」と判断した写真は、何度見せても「犬が写っている」という答えが返ってくる。
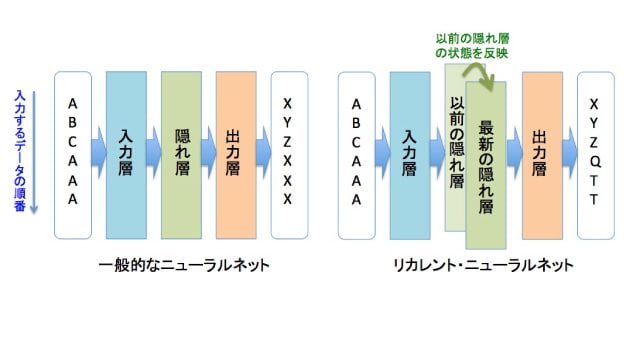
画像認識ならばこれで問題ないのだが、話し言葉や音楽の認識、先の展開の予測のような、時間の流れに依存する文脈を伴う課題には適用できない。別の機械学習法が必要になる。こうした要請に応える技術が「リカレント・ニューラルネットワーク(RNN)」である。RNNは、研究レベルでは、現在最も注目されている分野である。
RNNでは、前の時刻の隠れ層の出力を、次の時刻の隠れ層の入力としてフィードバックする(図4)。つまり、ちょっと前の自分の状態に学ぶ仕組みである。出力は前の状態に依存するため、同じ入力を与えてもその経過によって出力値が異なる。ソフトバンクロボティクスのヒト型ロボット「Pepper」の「感情生成エンジン」もRNNを応用している。会話の展開によって、同じ質問をしても違う答えができる秘密がここにある。
 |











-
21.3.22
タンパク質構造予測を可能にするAI

-
21.3.8
ロケットエンジンの課題を解決する「折り紙式」燃料タンク

-
21.2.22
AI顕微鏡は、数分でガン細胞を見つける

-
21.2.8
太陽エネルギーを数ヶ月から数年保存する新素材

-
21.1.26
完全にフラットな⿂眼レンズでカメラが変わる