JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Laboratories
- 研究室紹介
生き物の進化から学び、科学技術の発展を加速する。
- 東京工業大学 情報理工学院 小野研究室
- 第1部:
- 小野 功
- 2019.05.31

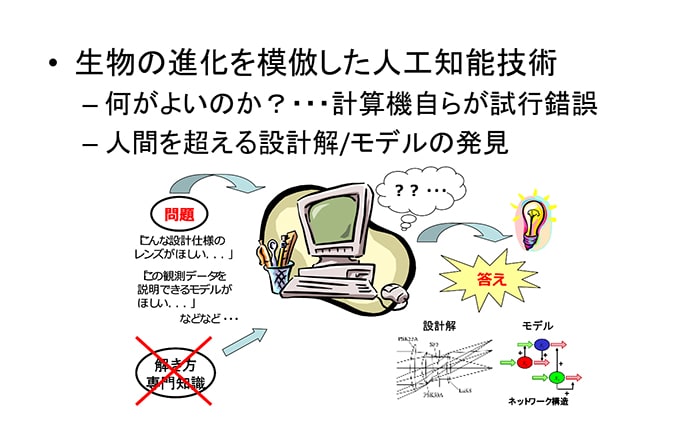
決められた手順に沿って仕事を正確・迅速にこなすコンピュータは、人工知能(AI)へと進化し、過去のデータから問題解決の方法を自ら学べるようになった。しかし、どんなに優秀なAIでもデータがなければ解法を学べない。何が起きるか一切わからない環境の中で、事前データがないまま問題を解決する ―― そんなAIが手出しできない問題解決に挑む方法を研究しているのが、東京工業大学の小野 功准教授である。未解決問題への取り組みは研究者や技術者に課せられた責務。そんな研究者や技術者の仕事を一気に加速させる可能性を秘めるのが小野研究室の研究する「進化計算」である。今回は同研究室を訪ね、科学技術の新たな武器となる進化計算の魅力と学生とともに新たな道を拓く取り組みについて聞いた。
(インタビュー・文/伊藤 元昭 写真/黒滝千里〈アマナ〉)
-

-
第1部:
東京工業大学
情報理工学院 情報工学系 准教授
小野 功
-

-
第2部:
東京工業大学
情報理工学院 情報工学系 博士課程1年
野村 将寛さん

前例のない問題に挑む手法を探求
── 小野先生が研究されている「進化計算」とは、どのような問題解決手法なのでしょうか?
小野 ── 進化計算とは、生物の進化過程を模倣して、試行錯誤によって最適解を見つけるアルゴリズムです。何らかの問題を解く際、解を求めるための解法マニュアルがあれば、それに従って解くのが一番効率的でしょう。しかし、問題によっては先人が残した事例や手本が全くないものもあります。そうなると、試行錯誤してみるしかありません。環境の変化に対応して生存競争を生き抜いた生物の進化過程は、まさに「手本のない問題解決」の典型です。そこから学び、前例のない問題に取り組む手法として体系化しているのが進化計算の研究です。
 |
── 暮らしや産業、社会の中には、進化計算で解くべきどのような問題があるのでしょうか?
小野 ── 身近な問題ではすでに進化計算が使われています。たとえば、N700系新幹線の先頭車両のノーズ形状の設計には進化計算が使われました[1]。新幹線のノーズ形状は、トンネルに突入する際に発生する騒音の軽減を求めて進化してきました。N700系以前には、設計者の経験を基に、世代が代わるたびにノーズを尖らせていきました。ところが、ノーズが尖り過ぎて、さらなる騒音低減を望むなら先頭車両に乗せる乗客を減らしたうえ、ホームに収まらないほど長くするしかないという状況になってしまったのです。一度「経験に基づく設計」から離れ、「事例や手本によらない設計」を考える必要が出てきました。
そこで進化計算の一種である遺伝的アルゴリズムを適用した結果、これまでとは異質な形状が設計解として見つかり、これまで以上の速度で運転しても大きな騒音が発生しないように設計できました。同様の手法は、国産旅客機MRJの翼の形状[2]やタイヤの形状[3]など、飛躍的な性能向上を求める機械設計の分野で使われています。
 |
── 熟練の設計者が一番手間をかける、泥臭いが付加価値の高い部分を進化計算で自動設計できているのですね。しかも、専門家の発想を超えた高度な解が得られているのが驚きです。最近、専門家の発想を超える解を得る手法として、機械学習系の人工知能(AI)に注目が集まっていますが、先ほどのノーズの設計はAIでは解けないのでしょうか?
小野 ── エキスパートシステムと呼ばれた一定のルールに沿って問題を解くかつてのAIは、解法マニュアルそのものでした。だから知識の蓄積がないと問題が解けません。そして、現在広く活用されるようになった深層学習(ディープラーニング)をはじめとする機械学習系のAIは、解法マニュアルは不要ですが、過去の事例から得られたデータがないと解を探り出せません。いずれにしてもAIでは、解を求めるためにマニュアルかデータが必要になります。
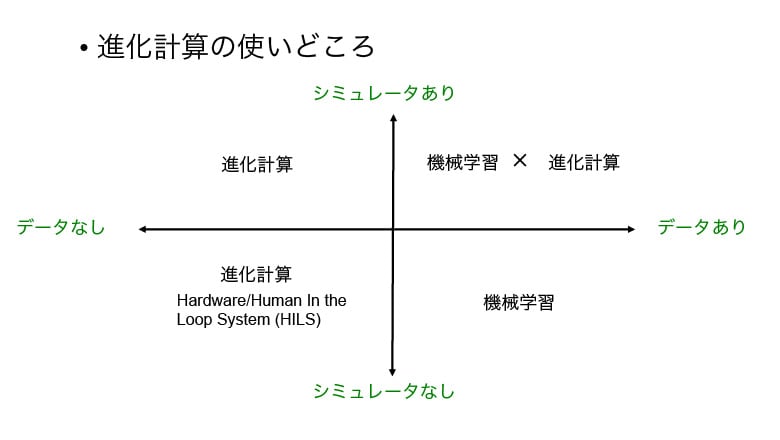
一方の進化計算は、未知の環境に放り出されて、一定の仕事の成果を出さなければならないような状況に向いている手法です。必要なのはシミュレータなどのブラックボックスな環境と、そこで達成すべき目的です。進化計算はこうした状況下で失敗覚悟の試行錯誤を繰り返し、得られた結果が目的に沿っているのかを評価しながらより良い解を探求していきます。
機械学習の分野では、環境からの報酬を手がかりに行動戦略を学ぶ「強化学習」と呼ぶ手法があります。試行錯誤による結果を評価し、より良い解を求める点で進化計算と考え方は同じです。ただし、強化学習ではロボットやエージェントなどの行動学習に特化した定式化になっているため、これらの問題では進化計算よりも効率よく学習を進めることができます。一方、進化計算は、強化学習が対象としているタスクにも適用可能であり、より汎用性の高い問題解決手法になっています。
 |
|
|
|
いかに試行錯誤を効率よく進めるか
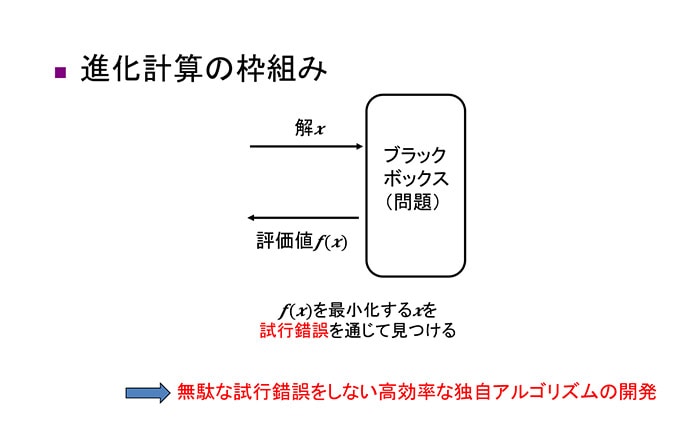
── 進化計算では、具体的にどのような手順でブラックボックス問題の解を求めるのでしょう?
小野 ── まず、評価値を求めるためのブラックボックスな環境を用意します。たとえば、新幹線のノーズ設計では、ノーズ周りにおける空気の流れなどを再現するシミュレータを用意します。そして、そこに勝手に設定した何種類かの解の候補を入れて環境で起きた現象を評価し、それが目的に合った良い解なのか悪い解なのかを評価します。そして、最も高い評価値を得た解を設計解とするのです。
ただし、このままでは単に試行錯誤しただけで終わってしまいます。むやみに解の候補をブラックボックスに入力したのでは、良い解を得るまでに時間がかかってしまいます。旅客機の翼の形状のような複雑な現象が関わるケースにおける解の評価は、シミュレータでひとつの解を評価するだけで一日がかりです。そのため、無駄な試行錯誤をすることなくより良い解を求める方法が求められます。ここが私たちの腕の見せ所です。
 |
 |
── どのようにして、効率化するのですか?
小野 ── もっとも古典的な進化計算の手法として、「ビットストリング遺伝的アルゴリズム(ビットストリングGA)」と呼ばれるものがあります。1970年代にジョン・H・ホランド氏が開発した、試行錯誤を効率化する手法です[4]。この手法では、解の候補を0と1のビットストリングで表現し、ランダムに設定した複数の解の候補を検証したあと、結果が良かった解同士の特徴を組み合わせて「次世代の解の候補」をつくります。こうした作業を何世代にもわたって繰り返すことで、複数の解の候補はだんだんと最適解の近くへとにじり寄っていきます。「良い結果が得られた解の候補には、良い結果をもたらす何らかの要因が含まれているに違いない」という仮定に基づいて、より目的に合った解を探求していきます。次世代の解を生み出す方法としては、二つの解の候補のビットストリングの間で、各ビットを50%の確率で交換することにより新しい解の候補を生成するという方法があります。この方法は、一様交叉と呼ばれますが、それほど効率よく優れた解を探り出せません。
── 世代が代わるたびに、何らかの戦略を盛り込む余地があるのですね。
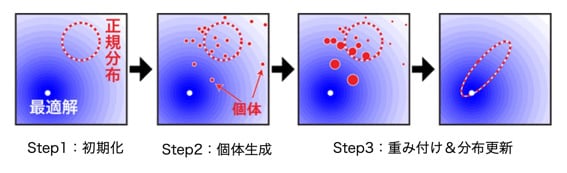
小野 ── その通りです。例として、最近、小野研究室で開発したDX-NES (Distance-based Exponential Natural Evolution Strategy)[5]と呼ばれるアルゴリズムをご紹介しましょう。DX-NESは、2008年にWirestraらが考案した自然進化戦略(Natural Evolution Strategy, NES)[6]を発展させた方法であり、ビットストリングGAよりもかなり少ない数の解の候補を生成するだけで効率よく最適解に近づくことができます。
DX-NESでは、まず任意の解を決めてその解を中心にした正規分布を考えます。変数が2つある2次元の問題では、平面内の1点を頂点にする山のようなすそ野を持った楕円形の確率分布を持つ領域になります。そして、正規分布に従って生成される解の候補の評価値の期待値を改善するように、正規分布の重心と形を学習します。具体的には、正規分布に従って第1世代の解の候補をいくつかつくり出します。続いてそれぞれの解の候補の評価値を求め、その評価値を基に重み付けし、次世代の解の候補を作るための正規分布の重心と形を定めます。こうすると、高い評価値が得られた解がある方向へと正規分布の重心がズルズルと動き、最適解がある方向により多くの解を生成できるようになるのです。
さらに、正規分布の重心が動いているときは、重心から遠い良い解の候補に大きな重みを与えて学習率を大きな値にし、それ以外のときは良い解の候補に大きな重みを与えて学習率を小さな値に設定するという工夫を導入しています。これにより、最適解から遠いときには、世代間での正規分布の重心が大きく動き、近づくと動きが小さくなり、さらに効率よく解を探り出せます。
DX-NESの解を探り出す効率は、簡単なベンチマーク問題である20次元Sphere関数で最適解を覆うように初期化領域を設定した場合、さきほど紹介したビットストリングGAの100倍以上に向上します。それまで、1,000万円もするPCクラスタでないと解けなかった問題が、1台の安価なPCで解けるようになってしまうのです。最適解を覆わないように初期化領域を設定した場合や、変数間に依存関係がある関数などの難しい問題になると、DX-NESは最適解を見つけられますが、ビットストリングGAは最適解を見つけられなくなってしまいます。アイデア次第でこうした劇的効果が得られる場合もある点が、この研究の醍醐味ですね。
 |
量子コンピュータの効果的活用に貢献
── すごいですね。アルゴリズムがハマった時はさぞ爽快でしょう。
小野 ── そうですね。これまでの情報処理の手法では、決して解けなかったような問題も工夫次第で解けるようになるのでやりがいのある研究だと思います。
たとえば、困難な問題として有名な「巡回セールスマン問題*1」と呼ばれる組合せ最適化問題も解くことができます。巡回セールスマン問題は、訪問先として複数の都市が与えられたとき、すべての都市を一筆書きで訪問する最短の巡回経路(最適解)を見つける問題です。巡回経路の候補の数は有限なので、原理的にはすべての巡回経路を洗い出せば必ず最適解を見つけられるはずです。しかし、都市数がたった30都市の問題でも、スーパーコンピュータを使ったとしても、生きている間には最適解が得られる保証がないほど長時間の計算が必要になります。
小野 ── そんな問題も進化計算を活用すれば、最適解を見つける保証はありませんが、かなり効率よく良い解を見つけることができます。たとえば、図5に示すような、10万から20万点のドットで点描された「モナ・リザ」や「ゴッホ」などの名画を対象に、すべての点をつないで一筆書きした場合の最短経路を求める6つのベンチマーク問題があります[7]。つまり訪問先が10万から20万都市ある巡回セールスマン問題というわけです。これらのベンチマーク問題では、訪問先が30都市の巡回セールスマン問題をはるかに上回る膨大な計算が必要になります。
この問題に対して、2013年に私たちの研究室で開発した進化計算アルゴリズムを、東工大のスーパーコンピュータTSUBAME2.0の30台の計算ノード上で並列に実行したところ、約5時間(10万都市問題)~約30時間(20万都市問題)で、これまでに知られている最良解(既知最良解)に対する誤差が約0.0063%(10万都市問題)~約0.0075%(20万都市問題)の解を得ることができました。
 |
小野 ── さらに、乱数系列を変えた同じアルゴリズムで、改めて6問それぞれの最短経路を求めるチャレンジを10回ずつ行い、得られた解の上位10%の解を合わせて次世代の解の候補とし、これを用いてさらに進化計算アルゴリズムで最短経路を求めました。その結果、10万都市、14万都市、16万都市、20万都市の4つの問題で既知最良解(発見された経路長はそれぞれ5,757,191、6,810,665、7,619,953、8,171,677)を発見し、12万都市と18万都市の2つの問題で既知最良解よりも良い解(発見された経路長はそれぞれ6,543,609、7,888,731)を発見することに成功しました[8]。
 |
── 目覚ましい成果ですね。巡回セールスマン問題は、量子コンピュータの一種である量子アニーリング・マシンが得意な問題だと思います。量子アニーリングに対する進化計算の優位性はどんなところにあるのですか?
小野 ── 量子アニーリング・マシンは、非常に魅力的なハードウェアだと思います。量子アニーリング・マシンの専門家ではないのではっきりしたことは言えませんが、多分、ハードウェアが順調に進化すれば、こうした問題は量子アニーリングのほうが効率よく解けるようになる可能性が高いと思います。ただし、量子アニーリングを上手に活用するには、進化計算の研究で得られた知見が有効に活用できると期待されます。シミュレーテッド・アニーリングや進化計算、タブー探索などは、最適化問題の解法の中でも類似の原理を基にしており、「メタヒューリスティックス」とよばれる最適化手法として一括りにされています。同種の手法ですから、実問題を量子アニーリング・マシンで解く問題に落とす際には同じ知見が役立つと考えています。
── 量子コンピュータの活用には、さらなるハードウェアの進化が求められると思います。すでに役立つ状態にある進化計算で腕を磨いておけば、量子コンピュータの全盛期が到来した際にもその知見を適用できるということですね。
小野 ── はい。いま、量子アニーリングのソフトウェア技術者が足りない、もしくは将来的に足りなくなると言われています。進化計算の研究を通して蓄積された知見は、将来の量子コンピュータ活用に役立つと期待しています。
進化計算は科学技術の進歩を加速させる
── 小野先生が進化計算の研究を始めたきっかけをお聞かせください。
小野 ── 学生時代から人の知的な活動、とくに設計手法などに興味がありました。効果的な設計や作業はどのように行われているのか、困難な問題とはそもそも何が難しいのか、知りたかったのです。学部3年生の時に人工知能関係の授業を受け、そこで遺伝的アルゴリズムが紹介されました。そこで簡単な試行錯誤の繰り返しで困難な問題が解けることを知り、その不思議な面白さに魅了されて、そこから今まで約25年間研究を続けています。
── この25年の間、進化計算のアルゴリズムはどのように進化したのでしょうか?
小野 ── より速く困難な問題を解ける方向へと進化しています。自然界では、驚くような進化が起きます。しかし、進化のスピードは極めて遅く、決して効率のよいものではありません。それを効率化することで現在の生物が到達できていないような能力を見つけ出すことができます。たとえば、鳥にインスパイアされて飛行機ができました。鳥が音速を超えて飛ぶことはできませんが、人がつくったジェット機なら可能です。進化計算は、超音速の領域で飛行機をさらに進化させるための解も探ることができます。
また現在では、変数が1万もあるような大規模なブラックボックス関数最適化問題も解けるようになってきています。多くの工学的問題では、変数は高々100程度です。しかし、ある複雑な現象を説明するためのモデルを構築するというモデリングの問題になると、さらに多くの変数を扱う必要が出てきます。たとえば、遺伝子間の相互作用のパラメータを決める医学・生物学の問題を扱う際には、前述した「変数が1万もあるような」大規模な問題が出てきます。進化計算では、こうした医学・生物学の問題の問題解決にも役立ちます。また、経済学的な現象をモデル化し、データにフィッティングさせるといった問題の解決にも役立ちます。モデリングの問題では、変数の数は1万にとどまらず、10万、100万の問題も存在しますので、さらなるアルゴリズムの性能向上が望まれています。
── 進化計算は、科学技術の進歩を加速させるツールのように思えます。そこから、どのような機械や技術が生み出されるのか楽しみです。
小野 ── 本当にそう感じます。ただし、そう簡単ではありません。研究では、ベンチマーク用の問題を使ってより高速に解ける方法を考案するのですが、ベンチマークで良い結果が得られても、現実の類似問題に適用したら思わしい効果が得られなかった――という場合が多いのです。
── 思わしくない結果になるのはなぜですか?
小野 ── 「ベンチマークの問題を解く」という目的だけのために最適化されたアルゴリズムになってしまうからです。現実の問題からベンチマークをつくる際に落としてしまった性質があるわけです。実際に役立つアルゴリズムにするためには、それを取り入れて困難な問題、複雑なプロセスに対応できるアルゴリズムへと進化させる必要があります。
── 効率化とは、基本的には「専用化」なのですね。
小野 ── そうなのです。実は、そのことは「ノーフリーランチ定理」[9]として知られています。ありとあらゆる問題に対応できる完全に汎用なアルゴリズムをつくろうとすると、結局は「もっとも非効率なランダムサーチと平均的な性能の観点で一緒になってしまう」というものです。そのため、現実の問題を解く効率を高めるには、工学や科学の分野において解くべき実問題に広く現れる性質を見つけ出して、これをうまく利用したアルゴリズムを作る必要があります。私たちは共通の性質を持った問題群を「問題クラス」と呼んでいますが、これをなるべく一般化しながら効率的に解ける問題の範囲を広げています。そのため、つくっては試しを繰り返しながら手法を進化させていく必要があります。
多くの試行錯誤を経て進化計算自体も進化する
── 今後、小野研究室ではどのようなことに取り組んでいくのでしょうか?
小野 ── さらに大規模な問題、解決困難な問題に取り組んでいきたいと思っています。互いに相反する多くの目的を同時に満たす解を求めるという「多目的最適化問題」と呼ばれる問題があります。多目的最適化問題は、目指す目的の数が増えると扱う変数も増え、問題自体がどんどん複雑になるのが特徴です。ところが、こうした問題は現実の製品開発などではよく見られる問題なのです。
複数車種の同時最適化のベンチマーク問題 [10]を例に挙げましょう。自動車業界では、クルマの製造コストを減らすため、小型車、SUV、大型車といった複数の車種の間で、なるべく同じ部品を使いたいという発想があります。部材を大量発注できるので、コストダウンできるからです。しかし、大型車の部材だけで小型車をつくると当然重量が増えますから、燃費が悪くなります。では、小型車に合わせればよいかというと、衝突安全性能の確保の観点から大型車には相応の部品を使う必要があるのです。つまり、共通部品点数と重量は、トレードオフの関係にあります。
こうしたトレードオフの関係が存在する問題には、最適解が複数存在します。これを「パレート解」と呼びます。共通部品の共通化を重視した最適解もあれば、重量の軽減を重視した最適解もあるのです。
── 確かに、複数の目的がある問題は、現実の生活やビジネス、社会の中に多くありそうです。
小野 ── こうした問題を迅速に解くことができれば、世の中に大きなインパクトを与えられます。それを求める人も多く、これらの問題を題材にして、多くの大学が解法を競うコンペティションが開催されています。
じつは、さきほどお話した「複数車種の同時最適化のベンチマーク問題」もコンペティションのために提供された問題です[11]。また、月探査の着陸船の最適な着陸地点を見つけ出す問題の解法を競うコンペティションも開催されました[12]。日陰になる日数を最小化し、地球との通信時間を最大化して、なるべく平らな着陸地点を選ぶというものです。
最近では、機械学習やロボットの制御でも同様ですが、研究を進めるうえでこうしたコンペティションへの取り組みがとても重要になっています。高等専門学校が積極的に取り組むロボコンも、高専生の技術力や学習意欲を高めるのに非常に役立っていると思います。明確な目標の実現に向けて多くの試行錯誤と失敗を経験することは、研究を推し進めるうえで非常に重要なのです。
得られた結果の背景にある本質を徹底的に探究
── 学生を指導する際、どのような点に気をつけていますか。
小野 ── ディスカッションを重視し、常に「なぜ」を問いかけて、本人に考えてもらうように心がけています。中途半端な状態で納得せず、上手くいっても、いかなくても、なぜそうした結果が得られたのかひたすら問いかけるよう指導しています。
── 試して得た結果の背景に何があるかを、しっかり自分の言葉で説明できるようになることが重要なのですね。
小野 ── とても重要です。取り組む問題が何なのかを言葉にできたら、研究としては相当いい線を行っていると思います。ゼミでは「1時間説明してもらって、その後1時間以上かけて研究室メンバー全員で質疑応答とディスカッションを行う」という時間をかけたスタイルで進めています。
ディスカッションの際は、まず、説明に用いる言葉の定義を明確にしてから議論を進めます。私たちの研究で扱う対象は抽象的なものが多いので、ディスカッションで用いる言葉を明確に定義しないと話が全く噛み合わなくなってしまうからです。そして、しっかりと問いかけができてはじめて、自分が持っていない視点を持つ人から貴重な気づきを得ることができます。研究の過程で得た結果に、時にもやもやとした違和感を覚えることがあります。しかし、そのことを誰にも語らないまま、意識の下に沈めてしまいがちです。それをまず言葉にして顕在化させないと、新しい知見は得られません。
── 研究室の学生には、どのようなことを期待していますか?
小野 ── 学生が社会に出た際、当然、研究室で得た専門知識も活かして欲しいのですが、それ以上に研究の過程で培った問題を言葉にできるスキルや、相手と情報交換して取り組むべき課題を見つけるスキルを活かしてもらえたらうれしいです。そして、人を幸せにする、ワクワクするような技術を開発してほしいと考えています。
  |
-
-
第1部:
東京工業大学
情報理工学院 情報工学系 准教授
小野 功
-
-
第2部:
東京工業大学
情報理工学院 情報工学系 博士課程1年
野村 将寛さん
[ 脚注 ]
- *1 巡回セールスマン問題:
- もともとは1940年代にアメリカのランド社が提出した懸賞問題。都市の数が増えるに従い、時間計算量が急速に増加するため、スーパーコンピュータでも最適解を求めることが難しくなっていく。そのため、ニューラルネットワーク、進化計算、アニーリング法、タブーサーチ法など、現実的な時間で近似解を求めるアルゴリズムが多く研究されている。アルゴリズムの性能評価のため、都市の数を10万や20万まで増やして、いかに短い時間で短い巡回経路を求められるかを試金石とするベンチマーク問題が作成されている。最大級のものとしては、世界中の190万4711都市からなるベンチマーク問題も作成されている。
- [1] 坂上 啓:
- N700系新幹線電車とその省エネルギー効果について,精密工学会誌,Vol.76, No.1, pp.41-45 (2010).
- [2] 大林 茂:
- 多目的最適化とデータマイニング, 日本機械学会誌, Vol.109, No.1050 , pp.383-385 (2006).
- [3] 小石 正隆:
- 進化計算による設計探査,日本ゴム協会誌,Vol.85, No.9, pp.289-295 (2012).
- [4] Holland, J. H.:
- Adaptation in Natural and Artificial Systems, Univ. of Michigan Press (1975).
- [5] Fukushima, N., Nagata, Y., Kobayashi, S., and Ono, I.:
- Proposal of Distance-weighted Exponential Natural Evolution Strategies, Proc. 2011 IEEE Congress on Evolutionary Computation (CEC), pp.164-171 (2011).
- [6] Wierstra, D., Schaul, T., Peters, J. and Schmidhuber, J.:
- Natural Evolution Strategies, Proc. 2008 IEEE Congress on Evolutionary Computation (CEC), pp.3381-3387 (2008).
- [8] Honda, K., Nagata, Y. and Ono, I.:
- A Parallel Genetic Algorithm with Edge Assembly Crossover for 100,000-City Scale TSPs, Proc. 2013 IEEE Congress on Evolutionary Computation (CEC), pp.1278-1285 (2013).
- [9] Wolpert, D. H. and Macready, W. G.:
- No Free Lunch Theorems for Optimization, IEEE Transactions on Evolutionary Computation, vol.1, pp.67-82 (1997).
- [10] 小平 剛央, 釼持 寛正, 大山 聖, 立川 智章:
- 応答曲面法を用いた複数車種の同時最適化ベンチマーク問題の提案, 進化計算学会論文誌, Vol.8, No.1, p.11-21 (2017).
- Profile

-
小野 功(おの いさお)
-
東京工業大学 情報理工学院 情報工学系 准教授
1970年生まれ。1994年3月東京工業大学工学部制御工学科卒業、1997年9月同大学院総合理工学研究科知能科学専攻博士課程修了。博士(工学)。同研究科リサーチアソシエイト、徳島大学工学部助手、同助教授、東京工業大学大学院総合理工学研究科知能システム科学専攻助教授を経て、2016年4月より現職。進化計算、最適化、強化学習などの研究に従事。
- URL: http://sacral.c.u-tokyo.ac.jp/
- Writer
-
伊藤 元昭(いとう もとあき)
-
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。
- URL: http://www.enlight-inc.co.jp/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
