JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Interview
- インタビュー
エッジAI時代を拓く
量子化したAIアクセラレータ
- 徳永 拓之
- LeapMind 取締役CTO(最高技術責任者)
- 2021.04.07

ディープラーニング*1を活用する動きが、多種多様な応用分野へと広がっている。これまでのディープラーニングは、学習や推論の処理をデータセンター内の高性能サーバーで実行することが一般的だった。そして、ICTシステム上に蓄積したビッグデータを対象にして、未来を予測したり、人間の眼では気付かない傾向を探り出したりする手段として使われていた。これが今、ディープラーニングの高度な認識力・洞察力を、身の回りにある家電製品や仕事で利用するオフィス機器、産業機器などエッジデバイスに組み込み、よりスマートな機械へと進化させる手段として利用されつつある。ただし、これまで高性能サーバーで実行していた処理を、非力なコンピューティング・パワーしか持たないエッジデバイス中で実行するためには何らかのブレイクスルーが必要になる。こうした時代の要請に応える技術を開発し、課題の解決策を提供しているスタートアップ企業がLeapMindである。同社 取締役CTO(最高技術責任者)の徳永拓之氏に、本格的なエッジAI時代の到来を見据えて取り組んできた同社での技術開発の経緯やこれからの展望について聞いた。
(インタビュー・文/伊藤 元昭 写真:小山 和淳〈アマナ〉)

突然やってきた新たな時代の幕開け
── ディープラーニングの応用を広げる技術を開発するスタートアップ企業として、LeapMindは注目されています。どのような経緯で設立されたのでしょうか。
徳永 ── 創業のきっかけは、創業者である松田総一が、ディープラーニングが世界を変える可能性を直感するできごとに触れたことにあります。2012年、画像認識技術の世界的な競技会であるILSVRC(ImageNet Large Scale Visual Recognition Challenge)で、まさに画期的なできごとが起こりました。それまで数%の認識精度を競っていた競技会の中で、ディープラーニングを画像認識に応用したチームが、他の手法を10%以上も上回る衝撃的な結果を叩き出したのです。これは、現在の人工知能(AI)ブームの起点となるできごとでした。
LeapMindの創業者である松田総一は、このニュースを聞いて、ディープラーニングが世の中を一変させる時代が来ることを確信したそうです。そして、その年の2012年末すぐにLeapMindを設立しました。
── まさに情報処理技術が新しい時代に突入する瞬間に創業したのですね。すぐに起業したフットワークの良さに驚きます。現在、LeapMindは、ディープラーニング技術の開発の中でも、AIチップに搭載するアクセラレータ回路の開発に注力しています。
徳永 ── 現在、私たちは、AIチップそのものを設計・製造しているわけではなく、半導体の上に乗せる回路、IP(Intellectual Property)*2を開発しています。CPUコアのIPを開発して半導体チップを設計する企業に提供するベンダーとしてArm(イギリス)が有名ですが、私たちも同様にAIチップの設計に利用するIPの提供に注力しています。チップ自体を設計・製造するビジネスに参入する意志はありません。このようにお話すると、最初からAI向けのアクセラレータのIP開発をしていたように聞こえるかもしれませんが、創業当初からIPにフォーカスしていたわけではないのです。
── 当初は、ディープラーニングに関連したどのようなビジネスを行う予定だったのでしょうか。
徳永 ── 最初は、「ディープラーニングの周辺に大きなビジネスが生まれる可能性がありそうだ」といった漠然とした衝動に突き動かされての創業だったようです。ただし、ビジネスをするからには、何らかの価値創出にフォーカスする必要があります。このため、まず実社会でディープラーニングを広く活用するために解決すべき課題を綿密に調査することにしたのです。課題の周辺にビジネスの種があるからです。
その結果、画像認識などを実行する際の推論処理では、高性能なコンピュータでなければ実行できないほどの莫大な数値演算や行列演算などを行うことになり、その際に膨大な電力を消費することが、応用拡大を阻害する要因になることが分かってきました(図1)。データセンターのサーバー上ならば高精度な画像認識などが実現できますが、パソコンや家電製品、産業機器などのAIを活用する現場(エッジ)に置く機器中で動かすことができそうもなかったのです。
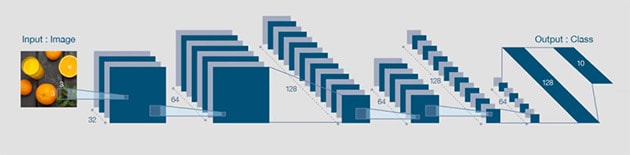
- [図1] ニューラルネットワーク*3の推論処理
- 複雑で膨大な数値計算・行列計算を繰り返し行っている

パラメータを量子化して、推論処理に必要な演算を大幅削減
── 応用を阻害する課題に着目し、その解決策にフォーカスしたビジネスを展開しようと考えたわけですね。どのような解決策を見つけたのでしょうか。
徳永 ── ディープラーニングに関する研究の成果を調査した結果、量子化と呼ぶ技術を活用すれば、ニューラルネットワークのモデルを単純化し、推論処理の演算量を減らせる可能性があることが分かってきました。それまでのディープラーニングでは、推論モデルを構成する際に、パラメータを32ビットの単精度浮動小数点で表現していました。量子化とは、より低ビットの整数による離散的な数値でモデルを近似して表現する技術のことです(図2)。演算の対象となるパラメータ自体が単純な表現になれば演算量が減り、ひいては消費電力の低減や演算回路のサイズを小さくして低コスト化できるようになります。つまり、AIを様々な機器に組み込んで活用できる可能性が拓くわけです。
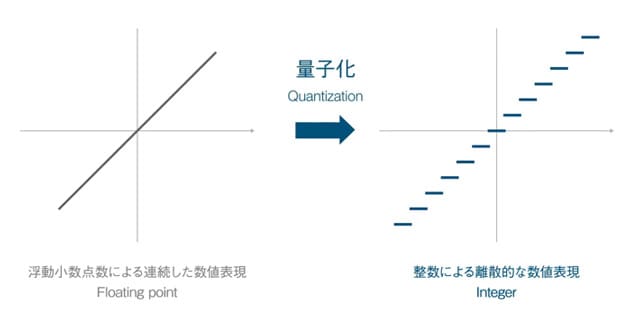
- [図2] 量子化のコンセプト
LeapMindでは、この量子化の考え方を発展させ、推論モデルの重み係数(Weight)を1ビットに、入力(Activation)を2ビットにまで単純化する技術を採用しています。こうすることで、演算効率を劇的に高めることも可能にしています。さらに、推論性能に与える影響が大きいことが知られているニューラルネットワークの第1層も、独自開発した「Pixel Embedding」と呼ぶ手法を利用することで量子化できるようにしました。これらを総合した技術を、「極小量子化」と呼んでいます。
── 極小量子化という独自技術を、AIチップを開発しようとしている企業などに向けて提供する手段として、IPを開発・提供しているのですね。
徳永 ── その通りです。ただし、最初からIPによる技術供与を考えていたわけではありません。まずは、量子化したニューラルネットワークをCPUで動かしてみました。すると、32ビット浮動小数点でパラメータを表現したのに比べれば消費電力は下がるのですが、劇的に下がると言えるほどの結果は得られませんでした。そこで、ハードウェアの専用回路をプログラムで書き込めるデバイスであるFPGA*4を活用して、量子化したニューラルネットワークを実装することにしたのです。これによって、消費電力はさらに下がりました。
ところが、その頃、Google(アメリカ)が、8ビット整数演算でモデル化したニューラルネットを使って推論処理を実行する「Edge TPU」と呼ぶASIC*5化した専用チップを市場投入するという噂が流れ始めていました。FPGAは、プログラムで簡単に専用回路を実装できる便利なデバイスですが、プログラマブルであることの代償として消費電力や絶対的な性能の面では専用チップには敵いません。
そこで、私たちもASIC市場に参入することにしました。しかし、ASICでもFPGAでも、開発言語は同じ(VerilogやVHDL)ですが、顧客からすると、初期費用やリスクの面で大きな違いがあり、FPGA用に開発されたIPをそのまま気軽にASICに転用はできません。ASIC化に耐えうる品質のIPであるということを顧客にご納得いただくため、Alchip Technologies(台湾)にご協力頂き動作確認や消費電力推定を行うなどの活動を行なった結果、ASIC化を検討するお客様ともいくつか前向きな会話を始めることができ、市場に参入しつつあります。
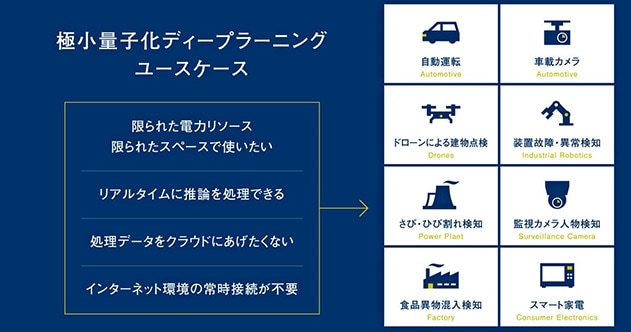
- [図3] 極小量子化ディープラーニングのユースケース
用途がはまれば、圧倒的効果が得られる尖った技術
── なるほど。市場での優位性を示せるビジネスモデルとして、IPを提供することにしたのですね。ディープラーニングによって高精度の画像認識などを行うためには、膨大なデータを基にした学習を行う必要があります。極小量子化を活用した推論処理を実行するためには、どのような学習をする必要があるのでしょうか。
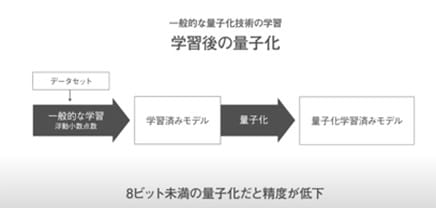
徳永 ── モデルを単純化しても推論の精度を低下させないようにするためには、量子化を見据えた学習をしておく必要があります。一般的な量子化技術の学習では、浮動小数点で表現したデータを使って学習した後のモデルを量子化による近似を行って、量子化した学習済みモデルを作っていました。この手順で極小量子化対応のモデルを作ると、推論精度が低下してしまいます。そこで、学習の段階から量子化することで、推論精度を高いレベルに維持できるようにしています(図4)。
 |
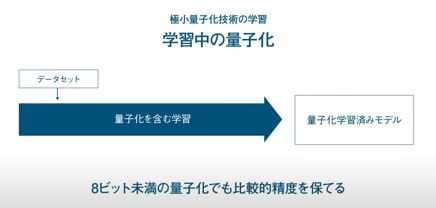 |
- [図4] 量子化を見据えた学習
- 一般的な量子化技術の学習手順(左)とLeapMindが採用した極小量子化技術の学習手順(右)
具体的には、ストレート・スルー・エスティメータと呼ぶ手法を活用しています。ディープラーニングの学習では、ニューラルネットワークに入力して得た推論結果と正解を突き合わせて、差分からパラメータの勾配を計算して重み係数を調整します。その時、量子化したデータを入力してしまうと、パラメータの表現が離散的な階段状に変化する関数になって、微分できなくなるので勾配を計算できません。そこで、学習時には階段状の数値表現ではなく、なめらかに連続変化する関数で近似すれば、学習できるようになるという方法です。LeapMindではそのための専用学習環境、極小量子化向けのツールやライブラリを用意しています。
── 極小量子化の適用を見据えた学習をしておく必要があるということですね。どのくらいのモデルの単純化が実現し、精度が得られるのでしょうか。
極小量子化したモデルは、していないモデルに比べて、最大でサイズを99%小さくすることができます。その一方で、推論精度はほとんど劣化しません(図5)。
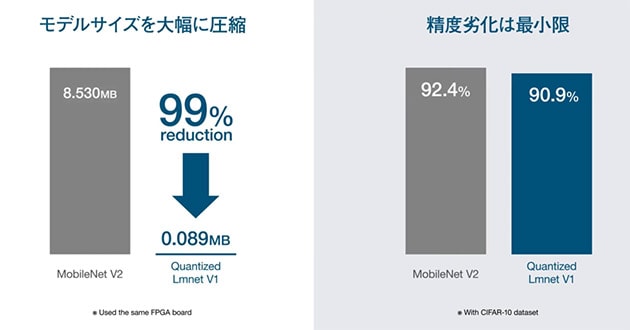
- [図5] 極小量子化を活用したディープラーニングの効果
- モデルサイズの圧縮効果(左)と精度の維持(右)
── 極小量子化は、どのような応用に適した技術なのでしょうか。
徳永 ── 極小量子化は、画像認識などに広く応用されている畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)への適用に適しています。量子化したCNNは、画像認識だけでなく、音声認識や分類にも適用可能であることを実験で確認しています。さらに、高精度な自然言語処理を実現する手法として注目されているトランスフォーマーにも適用可能であることが分かってきています。
画像認識の中でも、認識問題の複雑さによって、精度に多少の違いがあります。例えば、画像認識のベンチマークによく使われるデータセット「CIFAR-10」では32×32画素の画像を10クラスに分類するのですが、それなどは量子化してもほとんど精度が落ちません。その一方で、「ImageNet」と呼ぶ画像サイズが大きな画像を1000クラスに分類するものでは、何らかの方法で精度低下を補う必要があります。現在だと3ポイントくらい精度が落ちる印象です。低消費電力や低コストといった技術のメリットが際立つ応用、処理適性のある応用を選ぶことで、極小量子化の効果を引き出すことができます。

大手企業が狙わないニッチな市場を開拓
── 現在、ビジネス的にはどのようなフェーズにあるのでしょうか。
徳永 ── 超低消費電力AI推論アクセラレータIPの商用版を、2020年10月に「Efficiera(エフィシエラ)」という名称でリリースしました。現在、AIチップを独自開発する機器メーカーを中心に商談を進めています。既に、多くの企業様に興味を持っていただいており、採用に向けて働きかけています。
EfficieraをASIC化すれば、シミュレーション上では、27TOPS/Wの電力効率を実現できることを確認しています。現在開発中の次世代バージョンでは、さらに電力効率を高めることを目指しています。GoogleのEdgeTPUは2TOPS/Wと言われているので、純粋にそこだけを見れば、現時点で約10倍優れていることになります。ただし、EdgeTPUの製造に利用している半導体プロセスは不明ですし、8ビット整数のモデルと極小量子化のモデルでは出せる精度が異なるので、単純な比較はできません。
── いよいよビジネスとして本格展開する時期になったということですね。どのような応用から、市場開拓を進めていくのですか。
徳永 ── LeapMindの技術には、特長が際立ち、適性の高い応用が歴然としてあります。それこそが私たちの狙いでもあります。一番美味しい市場は、大手が狙うでしょうから、同じ市場を狙っていたらスタートアップ企業である私たちに勝ち目はありません。私たちの技術が光るニッチな応用から攻めていきたいと考えています。
応用の中心は、エッジデバイスへのディープラーニング機能の組み込みです。具体的には、まず家電製品向けにトライしていく計画です。日本に有力企業が多い、デジタルカメラへの応用を狙っていきます。デジタルカメラは、消費電力や価格など制約が厳しい製品であり、極小量子化の特長が際立ちます。物体検出、物体追跡、ノイズ除去、画像分類、超解像など、様々な画像処理に適用できることを確認しています。
── 同じく日本に有力企業が多い自動車などは、応用市場として想定しているのでしょうか。
徳永 ── LeapMindの技術は、認識の精度を極めるような応用に向いているわけではありません。自動運転車に使われるような走行環境の認識に適用し、人の命を預かるような用途への応用は現時点では荷が重いと考えています。ただし、危ない状況になったことを検知したら警告を出す、進入禁止の道路に入り込む前に知らせるといった補助的な応用には活用できるのではないかとも考えています。電気自動車では、バッテリに蓄えた限られた量の電力を利用して走っているので、クルマに搭載する電装品には低消費電力化が求められることでしょう。警告システムなどを量子化したディープラーニング・システムで実現すれば、低消費電力と精度を両立させることができるのではないでしょうか。将来的には、この辺りの効果を実証して、市場開拓していきたいと考えています。
── スタートアップ企業ならではの、市場開拓の手筋があるわけですね。
徳永 ── 技術戦略もスタートアップ企業ならではのアプローチを採用していると思います。私たちの技術は、ニッチな市場で際立った性能を発揮できるよう、かなり尖った技術に仕上げています。例えば、先述したように、極小量子化の潜在能力を最大限発揮させるためには、学習する段階から量子化する、独自の学習プロセスを経る必要があります。ユーザーにとっては、利用に際して、ひと手間掛かるわけです。こうした、言葉を替えればクセがあるが効果は大きな技術は、大企業では事業化できないと思います。その一方で、ユーザー企業も先進的な企業が中心になるのではないかと期待しています。
ただし、いくら先進的で、高性能化が期待できる技術だからといって、ユーザー企業の技術力だけを頼りにしていたのでは、商品とは言えないのではないかとも考えています。そこで、ユーザーが利用する際の手間を軽減する仕組みを用意し、提供しています。
ニューラルネットワークは、学習データがたくさんあるほど、精度が高まります。まずは、画像を分類する問題を多数こなして量子化対応の学習をしておき、ユーザー側でその一部を剥ぎ取って別のものを乗せて応用したいタスクを高精度で解けるようにします。これは、ファインチューニングと呼ぶ方法です。
私たちが提供するツールは、広く利用されているフレームワークであるTensorFlow上に機能拡張として組み込んだものになります。今後は、同じくユーザーが多いPytorchに対応したバージョンも出していく予定です。現在、TensorFlowやPytorchを利用しているエンジニアならば、技術的なハードルは高くはないと思います。

独自AIチップを求める日本企業は多い
── 世界的には、米国のGAFA*6や中国のBATH*7のようなプラットフォーマやTesla(アメリカ)などの自動車メーカーが、AIチップを独自開発する動きが目立ってきています。LeapMindのIPを使ってチップ開発するのは、家電メーカーや半導体メーカーになるのではないかと思うのですが、日本でAIチップを開発する機運は高まっているのでしょうか。
徳永 ── 日本企業の独自チップを開発する機運に関しては、一般的な海外企業よりも高いと感じています。もちろん、GAFAのような特異な存在に比べれば取り組みが目立たないように見えるかもしれませんし、半導体の開発・製造に要するコストが高くなって昔ほど気軽にASICを開発できる状況でないのも確かです。しかし、日本企業は、自社の競争力を高める独自技術を保有したいというマインドは高いと思います。デジタルカメラの分野は、その典型的な例です。ハイエンドの機種を発売しているのはほぼ日本企業ですから、私たちは先進的なユーザー企業にコンタクトしやすい場所にいるのだと言えます。その地の利を生かして、着実にユーザーを掴んでいきたいと考えています。
また、いきなりASIC化するのは、開発コストの観点からハードルが高いと考える企業も多いことでしょう。そうしたケースでは、「まずはFPGAに実装することから始めてみませんか」と提案しています。まずは、極小量子化によるAI推論アクセラレータの効果を実感していただくことが重要であり、FPGAにも実装できるEfficieraのメリットを生かした導入シナリオを提示しています。FPGAならば、Efficiera自体や周辺回路の改善を逐次進めることができますから、その時点で最も完成度の高い技術を投入できる安心感があります。また、Efficieraでは、スケーラブルな設計を採用しているので、FPGAの進化に合わせて高性能化させていくこともできます。
── これからの展開が楽しみですね。今後は、技術をどのように発展させていこうと考えているのでしょうか。
徳永 ── 市場環境や技術トレンドの変化が速い分野なので、予想が当たるとは思っていません。より多くの利用例を獲得すべく、目標は柔軟に変えていきます。ただし、技術面では、量子化すると価値が高まりそうな応用が複数ありますから、今後2、3年は量子化を軸に定めて技術開発していきます。
例えば、CNNを音声処理に適用できるという話をしましたが、現在の極小量子化技術を実際に適用するためには足りない機能があります。そこを埋めて、応用を拡大していくための準備をしていきます。また、回帰型ニューラルネットワーク(Recurrent Neural Network:RNN)のような仕組みを入れたほうがよいタスクもあります。RNNへの展開も見据えています。加えて、画像処理や音声処理にトランスフォーマーを適用することにも注目が集まり、現在CNNが適用されている応用で利用が広がる可能性があります。ここでの極小量子化の適用にも挑戦していきたいと考えています。
 |
 |
[ 脚注 ]
- *1 ディープラーニング:
- 対象の全体像から細部に至るまでの各々の粒度の概念を、深い階層構造を持つニューラルネットワークと関連させながら学習する機械学習の一種。ネットワークの層が多いほど複雑な判断を正確に行うことができる。
- *2 IP(Intellectual Property):
- FPGA、IC、LSIなどの半導体を構成する再利用可能な回路コンポーネントの設計情報。ソフトウェア開発における「ライブラリ」にあたる。
- *3 ニューラルネットワーク:
- 脳の神経網を模した、脳機能の特性の一部をコンピュータ上で表現するために作られた数理モデルのこと。ディープラーニングもニューラルネットワークの一種。
- *4 FPGA:
- プログラムによって専用の電子回路を実現できるセミカスタムICの一種。高集積、高機能で非常に多くのI/Oを持っており、ユーザーによる書き込みが容易であることが最大の特徴。開発サイクル短縮化に大きく寄与するため、ゲートアレイに替わって、様々な応用分野で活用されるようになった。
- *5 ASIC:
- 半導体ユーザーの要求に合わせて、特定用途に特化したセミカスタム半導体の総称。トランジスタなどの素子形成だけをあらかじめ済ませておいた半導体に、用途に応じた回路を形成する配線を施して、求める機能・性能の半導体を実現する。セミカスタム化するための手法には、ゲートアレイ、スタンダードセルなどいくつかの種類がある。
- *6 GAFA:
- インターネットサービスを主ビジネスとするGoogle、Amazon、Facebook、Appleの4企業のこと。
- *7 BATH:
- 中国におけるBaidu(検索サービス)、Alibaba(ECサービス)、Tencent(SNS)、Huawei(通信機器販売)の4企業のこと。
- Profile

-
徳永 拓之(とくなが ひろゆき)
-
LeapMind株式会社 取締役CTO
大阪大学 基礎工学部システム科学科卒業、東京大学大学院 情報理工学系研究科修了。ヤフー(株)、(株)Preferred Infrastructure、スマートニュース(株)を経て、2018年から現職。
- URL: https://leapmind.io/
- Writer
-
伊藤 元昭(いとう もとあき)
-
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。
- URL: http://www.enlight-inc.co.jp/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
