JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Interview
- インタビュー
社会を驚愕させたChatGPTなどの生成AIを生み出した、進化版ディープラーニング技術「基盤モデル」とは前編
- 倉田 岳人
- 日本IBM 技術理事
東京基礎研究所 AI Technologies担当
シニア・マネージャー
- 武田 征士
- 日本IBM 東京基礎研究所 Accelerated Discovery担当
プリンシパル・リサーチ・サイエンティスト兼グローバル・チームリーダー
- 千葉 立寛
- 日本IBM 東京基礎研究所
Hybrid Cloud担当
シニア・テクニカル・スタッフ・メンバー兼マネージャー
- 小原 盛幹
- 日本IBM 技術理事
東京基礎研究所副所長
Chief Software Engineer for Hybrid Cloud on IBM Hardware
- 2023.06.16

「生成AI」と呼ばれる新しいタイプの人工知能(AI)技術の威力に注目が集まっている。ディープラーニング(深層学習)の活用が広がって以来、AIは画像認識など特定作業で人間を超える認識精度を実現し、自動運転車やスマートファクトリーなどに利用されるようになった。今話題の生成AIでは、人間と自然な言語で対話しながら調査業務をこなし、プロが創作したかのような精緻なイラストや音楽などまで量産できる。囲碁の世界チャンピオンを倒すといった従来AIの成果も、十分驚きに値するものだったが、そうした成果は、大多数の一般人にとっては「他人事」だった。これに対し、生成AIの成果は、多くの人が職を失う危機感を感じるほどの「自分事」の技術革新として映っている。ただし、AIの専門家に言わせれば、こうした生成AIの衝撃も、これから始まる大変革の始まりにすぎないという。生成AIの代表例であるChatGPTなどは、「基盤モデル」と呼ぶ進化版ディープラーニングの威力を示す応用の一面でしかないからだ。日本IBM東京基礎研究所で、基盤モデルの技術開発と応用開拓に取り組む方々に、基盤モデルに秘められた可能性と今後の応用展開、社会に与えるインパクトなどについて聞いた。
(インタビュー・文/伊藤 元昭 撮影/氏家 岳寛〈アマナ〉)

“第3次AIブーム 第2波”、AIの威力をより多くの応用に
── 「基盤モデル」と呼ぶ新しいタイプのAI技術をベースに開発された、OpenAI(アメリカ)が開発した生成AI「ChatGPT」が話題になっています。IBMでは、基盤モデルの技術開発と商用化、応用開拓に、早い時期から取り組んでいると聞いていますが、そもそも、基盤モデルとは、どのような目的で開発された、いかなるAI技術なのでしょうか。
倉田 ── 人工知能(AI)技術は、ディープラーニング技術を活用することによって、「第3次AIブーム」と呼ばれる3回目の春を迎えました。そして、近年の生成AIの商用化によって、以前のブームでは来なかった夏を迎えつつあると語る研究者がいます。
これまでのディープラーニングは、画像認識、音声認識、自然言語の理解、さらには囲碁など、特定の作業(タスク)に限定適用することで、人間を超える能力を発揮する技術でした。加えて、高精度の推論を実現するためには、適用する個々のタスクごとに、莫大な量のデータを教材としてAIを学習させる必要がありました。つまり、目覚ましい成果を挙げる潜在能力を持つ技術ではあるが、期待する能力を具現化するためには、莫大な労力・時間・コストを費やして莫大なデータを収集し、AIに学習させる必要があったのです。これがAIを応用する上での実務的・経済的な高いハードルとなり、適用先が限定されていました。
基盤モデルは、ディープラーニングの威力を生かしたアプリケーションを、最小限の労力・時間・コストで生み出すことを目指して開発された技術です。大量かつ多様なデータで訓練された大規模なAIモデルであり、さまざまなアプリケーションに適用可能なAIを生み出す“基盤”となる役割を果たします(図1)。
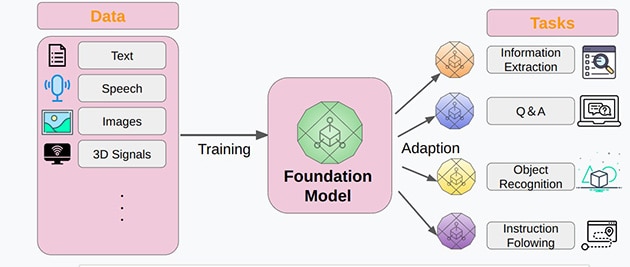
- [図1]基盤モデルのコンセプト
- 出典:東京大学 TRAIL
── 高精度な判断を下すAIを、より少ない労力で作り出すための技術なのですね。基盤モデルは、どのような手順で知識を学習させるのでしょうか。
倉田 ── 学習段階での従来のディープラーニングとの相違点は、学習を2段階で行う点にあります。まず、1段階目の学習として、応用が想定されるさまざまなタスクに共通する知識やスキルをAIに学習させます。こうして出来上がった汎用性の高いAIモデルを、基盤モデルと呼んでいます。ただし、出来上がった基盤モデルだけではタスクをこなすことができません。そこで、2段階目の学習として、出来上がった基盤モデルに少量データを追加学習させて、個々のタスクに適応化させます。この2段階目の学習を「ファインチューニング」と呼んでいます。1段階目で基盤モデルさえ完成させておけば、特定タスクに適用するAIモデルを格段に効率よく学習させることができます。
こうした基盤モデルを利用する学習では、学習に伴う作業を劇的に効率化できる重要な特徴があります。従来のディープラーニングでは、学習させるデータに、認識や処理の答えとなるラベルを付与したデータを大量に用意する必要がありました。これに対し、基盤モデルの学習では、ラベル無しデータで学習を進めることができるのです。これによって、データを用意する際の労力を大幅に削減できます。その一方で、ファインチューニングで利用するデータには、ラベルありデータを用意します。ですが少量を用意するだけで済むため、トータルな作業量で従来AIと基盤モデルベースのAIの学習を比べると、ずっと効率的に学習できます。

基盤モデルを活用して、自然な会話が可能なAIを作成
── ChatGPTなど、人間のように自然な会話ができるAIチャットサービスは、基盤モデルのどのような特徴を活用して作られているのでしょうか。
倉田 ── 人間のように会話できる生成AIは、会話文の中に登場した単語を基に、次に出現する可能性が高い単語を予測する大規模言語モデルで作られています。例えば、会話の中で「カラスは」という単語列が出てきたとしましょう。すると、私たちは、たぶん次には「黒い」という単語が現れるのではないかと無意識に予測しながら会話します。過去の会話や文章に基づく経験によって推測し、予想通りの単語が出てくると自然な会話として安心感を得るわけです。
同様にAIの言語モデルも、過去に書かれた文章などを学習することによって、人と同様の一見高度な知的能力に見える言語モデルに育てることができます(図2)。ただし、自然な会話を可能にするためには、莫大な量の文章を学習しなければなりません。

- [図2]言語モデルを育てて、自然な会話が可能なAIを育てる
- 写真:AdobeStock
画像データなどは、画素間やフレーム間での連続性が高いため、近隣に連続的に登場するデータの内容を予測し易い傾向があり、ディープラーニングの適用が比較的容易でした。これに対し言語はデータが離散的であり、直前の文節から次に登場する単語を予測しにくく、当初ディープラーニングの適用が困難でした。ただし、「ベクトル表現」と呼ぶ、似た意味の単語を近隣に配置できる手法の利用法が確立され、ディープラーニングの活用が可能になりました。そこに基盤モデルを適用することで、莫大なデータの学習の効率化が実現したのです。ChatGPTは、文脈などを加味しながら、より有益な文を生成できる方向へと進化しています。より高度な言語生成を可能にするうえで、基盤モデルの活用は欠かせません。
ちなみに、ChatGPTでは、大規模言語モデルだけではなく、生成した文が正しいこと、利用者の役に立ったことなどの観点から評価するAIモデルを併用して、評価結果を生成したモデルにフィードバックする仕組みも備えているようです。これによって、ユーザーの好みに寄り添い、感心するような回答や会話を作り出しているのです。
── イラストなど画像を生成するAIは、どのような仕組みで動いているのでしょうか。
倉田 ── 基盤モデル、大規模言語モデル、生成AIなどの用語が同じように使われていることも多いのですが、すべての生成AIが基盤モデルをベースに作られているわけではありません。要求した条件を満たす画像を生成するAIは、「拡散モデル*1」と呼ぶ、基盤モデルとは別のAI技術を基に作られています。こちらも、技術の進歩と応用の拡大が著しい領域です。

プログラム開発やゴルフ解説、衛星画像解析などにも応用
── 現在、基盤モデルは、どのようなアプリケーションで活用されているのでしょうか。
倉田 ── まず、これまで作ってきた特定タスク向けAIを、さらに機能向上させるために基盤モデルが使われています。例えば、これまで企業向けの文書検索ソフトウェアでは、質問を投げると関連文書の中にある該当する情報が含まれていそうな場所をリストアップして出力していました。これが基盤モデルを使ったAIでは、「日本IBMが設立されたのは何年ですか」といった質問を投げると、関連文書の内容を調べて「1937年」といったピンポイントの答えを示すことができるまでに進化しています。基盤モデルを活用すれば、こうした高度な機能を、簡単に実装できるようになるのです。
── 文書など言語を扱う領域では、特に活用が広がりそうですね。
倉田 ── 基盤モデルは、ChatGPTのような自然言語処理の領域での活用が、多くの人にとって成果がわかりやすく注目を集めがちです。しかし、技術的には自然言語向けに特化した技術ではなく、さまざまな種類のデータを扱うことができます。
例えば、私たちは、プログラムコードの基盤モデルを作って、プログラマーの開発を支援するアプリケーションも開発しました(図3)。Red Hat Ansible*2の設定ファイルを書く際、「このような設定を書いてください」と指定すれば、その設定を自動生成して出力するというものです。このアプリケーションを利用すれば、対話的にプログラムや設定ファイルを開発できるようになり、プログラマーの作業効率が高まります。こうしたAIを活用するためには、AIを利用する側にも一定のリテラシーが求められます。プログラマーの職を奪う存在ではなく、人間と共に働き、支援する存在であると考えています。

- [図3]プログラムのコードを自動生成し、プログラマーの開発を支援する
- 写真:AdobeStock
また、面白い用途として、ゴルフトーナメントのマスターズに、お気に入りの選手の一打一打を解説してくれる生成AIを導入しました(図4)。選手のショットデータを基に、解説のナレーションを自動生成できるように学習したAIで、2万件のビデオクリップを生成しました。すべての選手・ショットを解説してくれる解説者を用意することは難しいでしょうが、基盤モデルを活用した生成AIが自然な言語で解説することで観戦者の体験の質を高めることができます。

- [図4]ゴルフトーナメントでのすべてのショットを自動解説することも可能になった
- 写真:AdobeStock
また、アメリカ航空宇宙局(NASA)とIBMで協業し、衛星画像を基にした基盤モデルを構築しています。予め基盤モデルを作成しておくことで、洪水などの災害が発生している状況の把握や、土地の利用状況を把握するためのAIを、必要に応じて効率的に開発できるようになります。
[ 脚注 ]
- *1
- 拡散モデルとは、ノイズまみれのデータから、要求した条件に対応したデータを推定して抜き出す技術。画像を生成するAIを作るため、まず画像にランダムなノイズを徐々に当てていき、完全にノイズにまみれた画像にする。それを起点に逆向きに推定した際に、ノイズ除去後の画像と、元の画像の差分がなるべく小さくなるように学習する。
- *2
- Red Hat社(アメリカ)が開発するオープンソースの構成管理ツール。サーバー構築から構成の変更、動作確認、確認作業まで一連の作業を自動化できる。
- Profile
-

-
倉田 岳人(くらた がくと)
- 日本IBM 技術理事
東京基礎研究所
AI Technologies担当シニア・マネージャー -
2004年東京大学大学院情報理工学系研究科修了。同年、日本IBM入社。以来、同社東京基礎研究所にて、音声言語情報処理の研究に従事。2013年東京大学より博士号取得。現在は技術理事、東京基礎研究所AI Technologies担当シニア・マネージャーとして、音声認識、自然言語処理の基礎研究、および国内外事業部門との協業を推進。IEEE SLTCメンバー。IEEE、情報処理学会各シニア会員。博士(情報理工学)。

-
武田 征士(たけだ せいじ)
- 日本IBM 東京基礎研究所
Accelerated Discovery担当
プリンシパル・リサーチ・サイエンティスト兼グローバル・チームリーダー -
2010年慶應義塾大学大学院理工学研究科博士課程修了(工学博士)。同大学院特任助教、エコール・セントラル・リヨン客員研究員を経て、2012年日本IBM東京基礎研究所に入社。現在、IBM Researchの戦略組織Accelerated Discoveryのグローバル・リーダーシップチームに所属し、マテリアルズ・インフォマティクス(MI)用基盤モデルの研究開発リードを担当。国内外のMIに関する協業案件を多数手掛ける。
-

-
千葉 立寛(ちば たつひろ)
- 日本IBM 東京基礎研究所
Hybrid Cloud担当
シニア・テクニカル・スタッフ・メンバー兼マネージャー -
2011年 東京工業大学 情報理工学研究科 数理・計算科学専攻 博士課程修了。博士(理学)。同年、日本IBM東京基礎研究所に入社。以来、同社東京基礎研究所にて、ハイパフォーマンス・コンピューティングやビックデータのための大規模並列分散処理基盤やクラウドインフラストラクチャ、並列分散プログラミング言語の研究開発に従事。近年は、クラウドインフラストラクチャおよびAIアクセラレータを用いてAIモデル実行を最適化するシステムソフトウェアに関する研究を行っている。

-
小原 盛幹(おはら もりよし)
- 日本IBM 技術理事
東京基礎研究所副所長
Chief Software Engineer for Hybrid Cloud on IBM Hardware -
1986年に東京大学工学部を卒業し、日本IBM東京基礎研究所に入社。1996年米国スタンフォード大学にてPh.D. (Electrical Engineering) 取得。2021年にIBM技術理事、2022年に東京基礎研究所副所長に就任。メインフレームやAIアクセラレータなどのハードウェアによる差別化を実現するソフトウェアシステムの研究を行っている。
- Writer
-
伊藤 元昭(いとう もとあき)
-
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。
- URL: http://www.enlight-inc.co.jp/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
