JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Science Report
- サイエンス リポート
AIチップを巡って競い合う巨人たち
- 文/伊藤 元昭
- 2017.10.31

生活や社会を一変させる力を秘めた人工知能(AI)。そこに関連したビジネスでは、AIの潜在能力を解き放つAIチップを、いつ、誰が、どのような形で実現するのかに注目が集まり始めた。こぞってAIチップの開発に乗り出すIT業界や半導体業界の巨人たちの姿は、大いなる力を秘めた“聖杯”を求めて争う伝説上の権力者のようだ。ただし、各社が思い描くAIチップの仕様は驚くほど異なる。それは、現在のビジネスでの強みを強化しながら、なおかつ未来の飛躍を望めるAIチップこそが理想と考えているからだ。各社の既存ビジネスの立ち位置の違いが、そのままAIチップの違いになっている。連載第2回の今回は、AIチップに投入されている技術と各社チップの特徴を解説する。
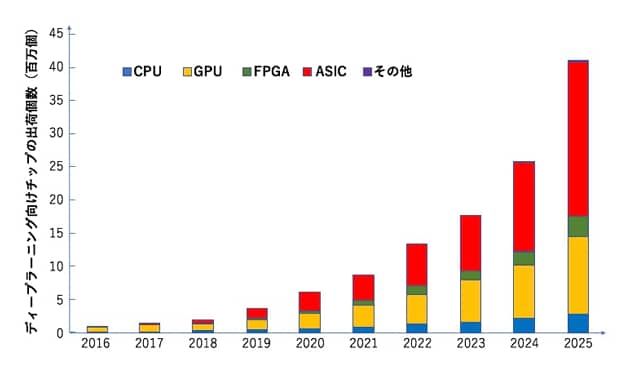
AI関連処理に向く内部構造を備えたAIチップが、巨大市場を形成することは確実だ。米国の調査会社Tracticaでは、ディープラーニング(深層学習)向けチップが、2016年に個数ベースで56万3000個、金額ベースの市場規模が5億1300万米ドルだったものが、2025年には4120万個、122億米ドルへと急成長すると予測している(図1)。その間の平均年成長率は42.2%と驚異的な数字になる。
 |
現時点でのAIを応用した情報システムは、巨大で莫大な電力を消費しながらも非力だった、真空管で作った黎明期のコンピュータと同じ状態だ。AI自体が目新しいため、特定分野で目覚ましい成果を上げているが、システム構築や運用のコストは巨額であり、お世辞にも使い勝手がよいとはいえない。
自動運転車にしろ、工場で予知保全を行うIoTシステムにしろ、多くのユーザがそのメリットを享受するには、AIチップの実用化を待つ必要があるだろう。AIチップの開発に着手している企業は、ベンチャー企業から巨大企業まで無数にある。
既存コンピュータの中核チップであるマイクロプロセッサでは、パソコン向け市場を制したIntelが、サーバからノート型パソコンまで市場で覇権を握った。そしてその後、スマートフォン全盛の時代になると、ARMのプロセッサコアが台頭。マイクロプロセッサ市場はIntel系とARM系の二頭体制になった。
AIが情報システムの中核を担うこれからは、こうした既存チップの勢力図は、一度ご破算になる。そして、まっさらな状態から市場争奪戦が始まるはずだ。いつ、誰が、どのようなAIチップで市場を制するのか、AIチップを投入する当事者も、またそれを使うユーザ企業も固唾を呑んで見守っている。
AIチップの3つの系譜
IT企業や半導体メーカが公表しているAIチップの仕様は極めて多様だ。従来のマイクロプロセッサでみられた仕様の違いレベルではなく、チップ全体の設計コンセプトからして異なる。各社とも、今後20年、30年と続くAI時代の自社ビジネスを担うチップを、技術の粋を集めて開発していることがうかがわれる。
ただし、大まかな分類ができないわけではない。各社のAIチップの仕様と内部構造に着目すると、以下の3種類に分類できる(図2)。
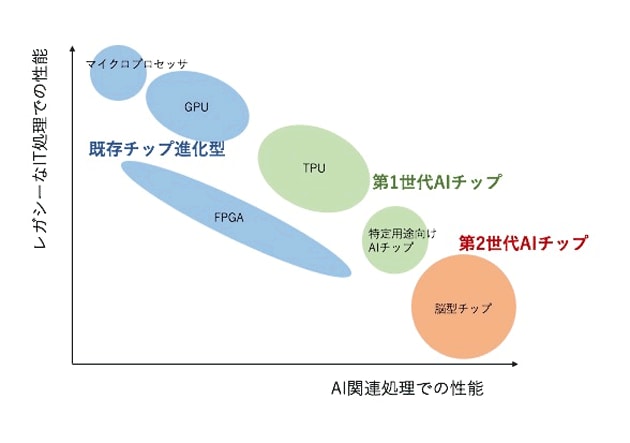 |
1つ目は、マイクロプロセッサやGPU*1、FPGA*2といった既存チップを、よりAI処理に向いた形へと進化させたAIチップ。ここでは仮に「既存チップ進化型」と呼びたい。Intel、NVIDIA、Qualcommなどの企業が、こうしたコンセプトのチップを作っている。メーカの顔ぶれをみても分かるように、パソコンやスマートフォンなど既存の応用市場での既得権者が並んでいる。既存の強みを生かしながら、時代の要請に応える機能を徐々に醸成させる算段だ。
2つ目は、AI関連処理にチップの内部構成を最適化させたAIチップ。ここでは仮に「第1世代AIチップ」と呼ぶ。連載第1回で、AIチップの処理対象となるニューラルネットワーク内での演算処理には、明確な特徴があることを解説した。簡単におさらいすると、推論処理では8ビット整数などで表現した低精度データの積和演算を、学習処理では16ビットや32ビットの浮動小数点などで表現した高精度データの積和演算を大量に実行する。第1世代AIチップでは、こうした演算処理の特徴に合った仕様を採用している。Google、富士通、MobileEyeなどがこうしたコンセプトのチップを作る代表的な企業だ。
3つ目は、ニューラルネットワークの機能と構造をハードウエアで模した、脳型チップである。ここでは仮に「第2世代AIチップ」と呼ぶ。前述した2つの系統のAIチップは、FPGAベースを除けば、基本的にプロセッサである。演算を実行するたびに、演算内容に沿った命令と演算対象のデータを読み込み、演算実行後にメモリに演算結果を書き込む。こうした処理システムのことをノイマン型コンピュータと呼ぶ。ところが第2世代AIチップは、ニューラルネットワークの中の演算機能をハードウエア化した、非ノイマン型という構造である。こうしたコンセプトのチップを作っているのが、IBMやNECだ。また、ベンチャー企業や大学でも盛んに開発している。
ここからは、3つの系統の代表チップについて、そこで使われている技術を詳細に解説していこう。まずは、Googleの「TPU*3」を例に、第1世代AIチップの技術を。その次に、既存チップ進化型に搭載されている技術と、その応用分野を。最後の第2世代AIチップの技術に関して、第3回の連載にて紹介する。
推論処理をGPUの25倍に高速化
第1世代AIチップの代表例であるGoogleのTPUは、AI関連処理に特化したチップの特徴を知るための絶好の題材である。同社は、学会論文や解説ドキュメントなどを大量に公開しているからだ。
TPUは研究開発段階のチップではなく、データセンターなどに投入されている実用化済みのチップである。同社のサービス、「Google検索」「ストリートビュー」「Googleフォト」「Google翻訳」には、既にTPUが使われている。
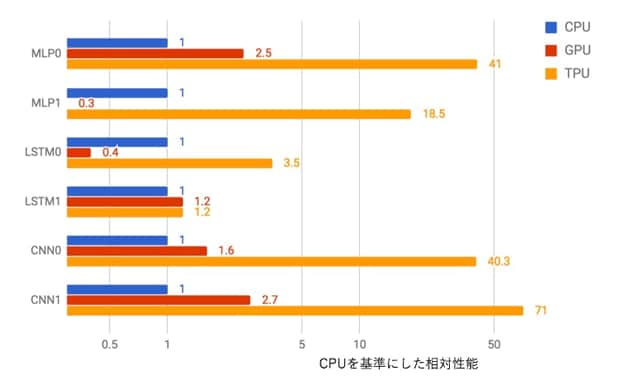
推論処理向けのTPUは、28nmプロセス*4で製造された動作周波数が700MHz、消費電力が40WのASIC*5である。動作周波数が3GHzを超えるものが当たり前のサーバ向けマイクロプロセッサに比べると、拍子抜けするほどゆっくりと動いていると感じるだろう。ところがGoogle社によると、一般的なマイクロプロセッサやGPUを使ってニューラルネットワークの計算処理を実行した場合より、15~30倍も高速であるとしている(図3)。さらに、単位電力当たりの性能で比べると30~80倍と、その高効率さが際立つ。
 |
ちなみに、単にTPUと呼ばれるチップは推論処理に特化したチップであり、学習処理の高速化を狙った「Cloud TPU」と呼ばれるチップが別にある。そして、TPUやCloud TPUの開発には、新進気鋭のAI研究者や半導体エンジニアに加え、David Patterson氏やNorman Jouppi氏など、マイクロプロセッサの進化をリードした、野球で言えば王・長島クラス、歌手で言えばビートルズクラスの一時代を作ったレジェンド研究者が現役で参加している。新しい時代を万全の布陣で開こうと意気込む、業界の空気が感じられる。
あの手、この手でAI関連処理を高速化
TPUでは、推論処理に欠かせない膨大な積和演算を効率的にするため、あの手この手の技術を併用している(図4)。ここでは代用的な4つの技術を紹介したい。
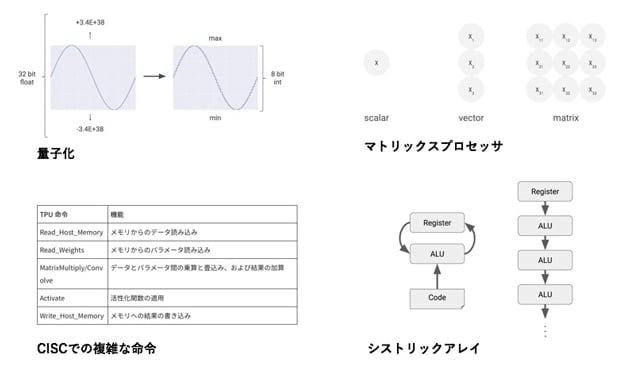 |
まず、「量子化*6」と呼ぶ技術を使って、32ビットといった高精度の演算対象データを、一律に8ビットへと精度を落としてしまう。Googleによると、画像認識用のニューラルネットワークの場合、元々91Mバイトあった処理対象のデータは、量子化によって1/4の23Mバイトまで削減できるという。さらにこの処理と並行して、浮動小数点演算を整数演算に置き換えてしまい、演算器の回路規模と消費電力を大幅に削減している。
一般的なGPUでは、1個のチップに数千個の32ビット浮動小数点乗算器を搭載している。ところがTPUでは、演算器1個当たりの回路規模が小さくなった分、演算器の数を増やし、8ビット整数乗算器を6万5536個も搭載している。推論精度のわずかな違いを許すことで、乗算器の数を25倍に増やし高速化しているのだ。
次に、複雑な演算の命令で実行できる、「CISC*7」というプロセッサの古典的なアーキテクチャを復活採用している。TPUでは、推論処理で用いる複雑な演算を1つの命令で実行できる、専用命令を十数個も用意した。これによって、データや命令の読み出しや書き込みの作業を最小限に抑えている。
またTPUでは、同じ演算を実行するプロセッサコアを、2次元的に数多く配列した「マトリックスプロセッサ*8」と呼ぶコアの配列法を採用している。これによって、クロック信号*9の1サイクル当たり、数十万回の演算を実行できるようにしている。Googleの言葉を借りれば、「マトリックスプロセッサの採用で、1文字ずつ印刷するタイプライタのようだったマイクロプロセッサの処理が、TPUでは1ページ分の文書を一括印刷するプリンタのように高速化した」という。
さらに、大規模なマトリックスプロセッサをチップ上に実装する方法として、「シストリックアレイ」という、従来のCPUやGPUとはまったく異なる構造を採用している。通常のプロセッサでは、プログラムに記された命令に沿って演算された結果は、演算を終えるたびに、演算対象データの一時保管メモリであるレジスタに保存される*10。ところがシストリックアレイでは、演算結果をレジスタに書き戻さず、次の演算の入力に回してしまう。その結果、TPUは、一般的なCPUに比べて83倍、GPUと比べても29倍という電力性能比を実現している。
学習処理向けAIチップの開発も着々
Googleは、2017年に学習処理向けAIチップ、Cloud TPUの存在を明らかにした(図5)。現時点では詳細な仕様は明らかになっていないが、1チップ当たりの性能は45TFLOPSであり、機械翻訳のモデルを学習させた場合には、最速のGPUより4倍も高速であるということが分かっている。これらの情報から推測すると、16ビット浮動小数点演算器を搭載しているとみられる。
 |
高精度の浮動小数点演算の実行が欠かせないとされる学習処理だが、ここでも演算を単純化できる可能性を示す研究結果が出てきている。富士通は、8~16ビットの整数演算器を用いてディープラーニングの学習結果を処理しても、推論処理の品質をほとんど低下しないようにできることを示した。手書き文字認識では、32ビット浮動小数点演算での学習処理によって98.90%だった認識率が、16ビットで98.89%、8ビットでも98.31%と、ほぼ変わらないという。そして消費電力は、16ビットで50%、8ビットならば約75%削減できる。同社は、2018年に出荷予定のAIチップ「DLU*11」に、この技術の組み込みを目指している。
既存チップをAI関連処理向けに改良
GPUは、元々3次元グラフィックス処理の高速化を想定して作られたチップだ。3次元グラフィックス処理では高精度の浮動小数点演算が必須になるため、学習処理向きの機能が漏れなく搭載されている。ただし、推論処理での演算精度に関してはオーバースペックである。
推論処理というのは、自動運転車や工場の検査装置、監視カメラの画像認識など、様々な機器への搭載が想定されており、潜在市場は巨大だ。このためGPUメーカは、製品に第1世代AIチップのエッセンスを盛り込み、仕様を寄せてきている。これが既存チップ進化型のAIチップである。
GPU最大手のNVIDIAは、2016年後半に出荷を始めた製品「Tesla P4」や「Tesla P40」に8ビット整数演算を高速に実行する専用命令を投入した。さらに、サーバ向けの最上位GPU「Tesla V100」には、「Tensor Core」と呼ぶ積和演算を高速化する演算器を搭載。推論では16ビット浮動小数点演算を、学習では16ビットと32ビットが混在する演算を実行する。また、Microsoft社は、ヘッド・マウント・ディスプレイ「HoloLens」向けにAIチップ「HPU(Holographic Processing Unit)*12」を開発したが、このチップはTensilicaのDSPコアにAI用の命令を追加して、24個集積したものだ。このチップも既存チップ進化型の流れを汲んでいる。
GPUと同様にAI関連処理に利用されている既存チップであるFPGAは、プログラムによってチップ内の回路構成を自由に変更可能だ。このため、比較的無駄のないニューラルネットワークを構成できる。ただし欠点が1つある。学習処理に不可欠な浮動小数点演算ができないことだ。Intelは、買収したFPGAメーカAlteraの製品「Arria10」に、32ビット浮動小数点乗算器と加算機を搭載して、AI関連処理への適性を高めた。
また、マイクロプロセッサもAI関連処理に適応するための機能を搭載するようになってきた。Intel社は、サーバ機向けのマイクロプロセッサ「Xeon Phi」の機能を強化し、16ビット以下の浮動小数点演算を高速化した。科学計算などではあまり使わない低精度の浮動小数点演算を強化している点に、AIの学習処理での競争力を高めようとする意図がみえる。
様々なニューラルネットに対応できる汎用性
ニューラルネットワークの形には、様々な種類があり、応用によって使い分けられている(図6)。例えば、画像認識処理で高精細な画像を扱うときには、入力パラメータの数を増やす。「犬」や「猫」といった認識結果の項目が増えれば、出力パラメータの数を増やす。また、より高度な認識で正答率を高めたいと思えば、層を深くする。音声認識のような言葉の文脈を認識に活かしたい場合には、処理履歴を反映できるニューラルネットワーク・モデルを利用する。といった具合だ。
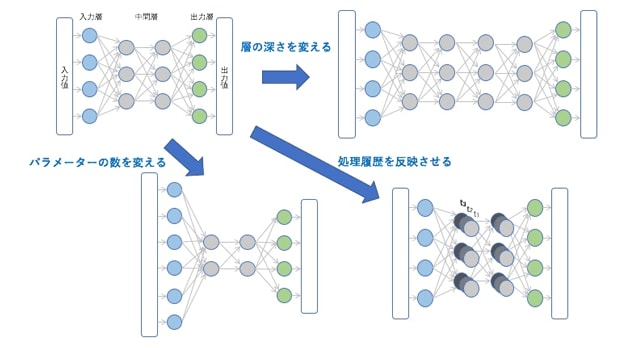 |
TPUは、特定のニューラルネットワークだけに特化したチップではない。AI関連処理に特化するための技術は投入しているが、様々な種類のニューラルネットワークにおいて、計算処理を高速化できる汎用性は維持している。これは、どのような応用のAI関連処理でも、高速に実行する必要があるデータセンターのサーバへの搭載を想定しているからだ。また、ディープラーニングは発展途上の技術であり、より進化したモデルが開発されても困らないような発展性も求められる。
TCPのような第1世代AIチップは、GPUなど汎用性の高いチップから、AI関連処理では必要のない機能を大胆に削り取ったチップであると言い換えることもできる。では、特定のニューラルネットワークの形に特化してAIチップを開発すれば、もっと高速化できるのか。実際にそのようなコンセプトで作られたAIチップが存在する。MobileyeのADAS(Advanced Driver Assistance System:先進運転支援システム)や自動運転車向け画像認識チップ「EyeQ」がその代表例だ。自動運転車で撮影した画像を認識する用途では、カメラの解像度や分類すべきモノの項目数、求められる精度などが一義的に定義しやすい。このため、汎用性を求めずに、無駄をさらに削ぎ落とした専用AIチップを開発できる。
AI処理への適性だけが、市場価値ではない
AI関連処理をより高速に、より低消費電力で、より低コストに実行することが、AIチップの存在意義である。そうした尺度でみれば、既存チップ進化型よりも第1世代AIチップや、第2世代AIチップが圧倒的に優れている。では、いずれ第2世代AIチップ一色になるのかといえば、恐らくそうはならない。
チップとしての市場価値は、AI関連処理への適性だけでは決まらない。ADASなどの画像認識処理に用途を限定したEyeQは、確かに高性能だが、それをデータセンターのサーバに乗せることはできない。画像認識以外の応用でのAI関連処理には向いていないからだ。だからこそ、様々なニューラルネットワークに対応できるTPUの存在価値がある。
既存チップ進化型も同様である。AI関連処理だけではなく、プログラムに沿った制御処理やグラフィックス処理などを併用するシステムでは、既存チップ進化型の活躍の場が大きく広がる可能性がある。その代表的な応用が、自動運転車である。近年、自動運転車の開発を狙って、多くの自動車メーカがAIの研究開発力の増強を急いでいる。こうした動きをみると、自動運転はAI技術のみで実現できるように思えてしまうが、実際はそうではない。
自動運転車の中での処理を少し詳しくみると、4つの作業に分類できる(図7)。カメラやセンサで情報を取得し、意味のある情報を抜き出す「情報収集」。取得した情報の意味を解釈して、クルマや周囲の状況を把握する「分析・認識」。把握した状況を基に、どのようにクルマを動かすのかを決める「行動決定」。コンピュータの指示にしたがって、アクセルやハンドル、ブレーキなどを的確に制御する「機構制御」だ。
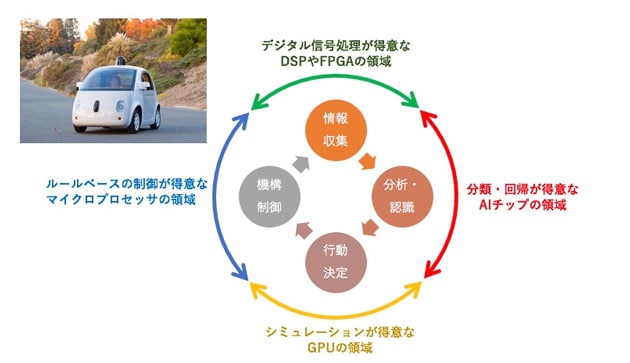 |
このうち、AIチップの適性が高いのは「分析・認識」の部分である。「情報収集」ではデジタル信号処理での性能が求められるため、DSPやFPGAが向いている。「行動決定」は、周辺状況をモデル化してクルマの動きをシミュレーションする処理の性能が求められるため、GPUが最適だ。「機構制御」はプログラムで定められた手順に沿って、多様な状況に対処できる汎用的な性能が求められるため、マイクロプロセッサ向きである。
IoTデバイスでは既存チップ進化型が求められる
初期の自動運転車は、4つの作業を1チップでは実現できないため、様々な種類のチップを併用することになるだろう。しかし、いずれ、複数の作業が1チップで実行できるようになると、多機能チップが求められる。既に、NVIDIAが、GPUとマイクロプロセッサなどを1チップ化した、画像認識用SoC「Xavier」を市場投入し、こうした流れに先手を打っている。
自動運転車に限らず、監視カメラや、工場で製品をモニタリングするセンサ、IoT機器などでは、AI関連処理による高度な「分析・認識」に「情報収集」「行動決定」「機構制御」といった機能を組み合わせて搭載することになる。こうした応用では、既存チップ進化型のAIチップが多用されることだろう。連載の第3回では、第2世代型AIチップである脳型(ニューロモーフィック)チップの開発動向を中心に、未来への方向性を解説する。
[第3回へ続く][ 脚注 ]
- *1GPU
- GPUとは、Graphics Processing Unitの略。グラフィックス処理や画像処理に特化した、専用の演算器と内部構造を持つプロセッサ。マイクロプロセッサのように、様々な命令を効率よく処理することはできないが、大量のデータを対象にして同じ演算を同時実行する並列処理に向いた内部構成を取っている。近年では、その優れた演算能力を生かして、科学計算などに活用するようにもなってきた。こうしたGPUの利用法を特に「GP(General Purpose)GPU」と呼んでいる。
- *2FPGA
- FPGAとは、Field Programmable Gate Arrayの略。プログラムを書き込むことで、思い通りの専用回路を自由に実現できるチップ。LUT(Look Up Table)と呼ぶ、自由に書き込める数値や論理の対応表(掛け算九九の表のようなもの)を多数並べて、それを複雑な配線でつなぎ、様々な演算回路を実現する。必要な回路を必要な分だけ作り込むことができるため、プロセッサに比べて演算時に消費する電力を削減することができる。
- *3TPU
- TPUとはTensor Processing Unitの略で、Googleが開発したAI関連処理、特に推論処理の高速化に特化して設計したAIチップの名称。名称の中のテンソルとは、複数の数をひとまとめにして、その集まりを1つの数として扱って演算するときの数の表現手法である。高校の数学で学習する、ベクトルや行列など、複数の数をまとめて演算する方法は、テンソルの一種である。複数の数を一列に並べてひとかたまりにしたものは1階のテンソル、つまりベクトルになる。2次元的に並べた場合には、2階のテンソル、つまり行列になる。もっと複雑な3階、4階・・・といったテンソルもあり、物理学で扱う様々な現象を表現するためによく使われている。テンソルの演算では、かたまりの中に含まれる数同士の積和演算を繰り返し行うことになる。複雑なAI処理では、こうした演算を実行することになるため、GoogleはAIチップの名称をTPUとした。
- *428nmプロセス
- 半導体チップに搭載される微細なトランジスタの最小線幅が28nmとなるチップを作る製造技術を、28nmプロセスと呼ぶ。この最小線幅が小さいほど、高速で、大規模な回路を搭載したチップを作ることができる。現在、既に10nmプロセスのチップが実用化され、パソコンやスマートフォン向けに投入されている。GoogleのTPUはそれよりも古い世代の技術を使っており、逆を返せばまだまだ進化する余地が十分あると言える。
- *5ASIC
- ASICとは、Application Specific Integrated Circuitの略で、特定の応用分野に向けて機能や性能を特化した専用半導体チップを簡単かつ短期間で設計・製造するための方法。あらかじめ、チップ上にトランジスタをたくさん作り込んでおき、チップに搭載する電子回路を設計した後に、設計図にしたがって、トランジスタ間を配線して専用半導体チップを完成させる。配線前は、すべてのチップ共通であるため、配線工程だけで済む分、製造が楽になる。
- *6量子化
- ニューラルネットワークの演算における量子化とは、あらかじめ設定した最大値と最小値の間の値を8ビットといった低精度の整数で表現し、データの情報量を圧縮する手法のことを指す。
- *7CISC
- 既存のプロセッサでは、動作周波数の向上を狙って、処理する命令の種類を絞り込んだRISCと呼ぶアーキテクチャを採用している。そもそも、このRISCアーキテクチャを開発したのが、TPUの開発に参加しているPatterson氏である。RISCでは、乗算と加算を何度も繰り返す複雑な演算は、単純な演算の命令を数多く組み合わせて表現し、プログラムを書いている。そして、命令を処理する度にデータの読み出しや書き込みの作業が発生するため、処理手順は複雑になる。
- *8マトリックスプロセッサ
- 通常のマイクロプロセッサでは、プログラムに書かれた1つの命令につき1回だけ演算を実行する。こうしたプロセッサのことをスカラプロセッサと呼んでいる。一方でGPUなどでは、数多くのデータを同時に演算するため、同じ演算を実行する数多くのプロセッサコアを横一列に並べた構造を採用している。こうしたプロセッサのことをベクトルプロセッサと呼ぶ。マトリックスプロセッサは、このベクトルプロセッサをさらに発展させたものだ。
- *9クロック信号
- 一般的なデジタル電子回路は、一定のサイクルに沿って、処理を実行している。メトロノームで全体のベースを参照しながら、音楽を演奏するのと同じである。このサイクルを刻む信号のことをクロックと呼ぶ。パソコンのマイクロプロセッサの性能を示す指標に、1GHz動作といった表現があるが、これはクロック信号が1GHz、つまり1秒間に10億回脈動して処理を実行していることを指す。
- *10
- 一見面倒な命令ごとのレジスタへの書き込み動作が、プロセッサを万能計算機たらしめているのだが、その一方で消費電力や回路規模を増大させる要因にもなっている。TPUでは、演算の内容自体は積和演算だけなので、汎用性に背を向けた構造を採ることができるのだ。シストリックアレイは、非ノイマン型に一歩近づいた技術であると言える。この他にも、マイクロプロセッサで汎用性を高めるために搭載されている大規模な制御回路が、TPUでは大きく簡略化されている。
- *11DLU
- Deep Learning Unitの略。富士通のAIチップの名称であり、ディープラーニング関連処理に特化した内部構造を採用しているための、このように命名された。
- *12HPU
- Holographic Processing Unitの略。MicrosoftのAIチップの名称であり、同社の仮想現実用ヘッド・マウント・ディスプレイ「HoloLens」にAI関連処理を盛り込むために設計されたたため、このように命名された。ちなみに製品名中にホログラフィックという言葉が含まれているが、HoloLensに採用されているのは立体画像を作り出すホログラムとは別の技術である。
- Writer
-
伊藤 元昭(いとう もとあき)
-
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。
- URL: http://www.enlight-inc.co.jp/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
