JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Science Report
AIチップが開く、新しい情報処理のパラダイム
- 文/伊藤 元昭
- 2017.11.30

AIチップの進化と利用は、今始まったばかりだ。これから何十年もの間、様々な技術が継続的に投入されることによって進化し続け、それぞれの時代で求められる有用な応用を次々と生み出していくことだろう。ただし、AIチップもコンピュータの一種であることには変わりない。現在のコンピュータが抱えている固有の技術課題は、AIチップを進化させる上でも問題になる。特に、「フォン・ノイマン・ボトルネック」と呼ばれる、コンピュータの高速化を阻む本質的な課題を解決しない限り、AIチップの成長シナリオは描けない。連載第3回の今回は、未来のAIチップが進化し続けていくための道を開く「脳型チップ(ニューロモーフィック・チップ)」の開発動向を解説する。
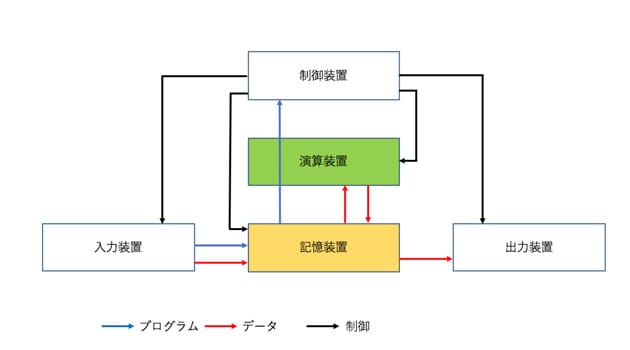
現在使われているほとんどのコンピュータは、約70年間使われ続けてきた、たった1つの基本原理に沿って作られている。天才数学者のジョン・フォン・ノイマンが考案したと一般に言われている「ノイマン型アーキテクチャ*1」という汎用計算機の構造である(図1)。様々な演算を自在に実行できる汎用性を強みに、代わるものがない価値を誇ってきた技術である。ワープロやウェブの閲覧、ゲームなど、様々な用途に利用できる汎用性の高いパソコンは、ノイマン型だからこそ実現可能なものだ。
 |
前回解説したGoogle社の「TPU*2」のような第1世代のAIチップも、スマートフォンや家庭用ゲーム機のCPUも、全てノイマン型をベースにして作られている。
ノイマン型ベースでは性能向上が困難に
コンピュータ界に長年君臨してきたノイマン型だが、70年を経て、さすがに技術的な疲弊が見えてきた。根本的な対策を取らない限り、これ以上の高性能化は望めない本質的欠点があるのだ。
ノイマン型では1つの演算を実行する度に、演算装置が記憶装置から命令とデータを読み込み、演算が終わった命令は破棄し、結果を記憶装置に書き込む。各プログラムに沿って、こうした作業を繰り返していくわけだ。これは遠い職場に毎日通うようなもので、一見、まどろっこしい手順だと感じるかもしれない。だが、命令をひとつひとつ確認し、データを必ず所定の位置に置きながら慎重この上なく働くからこそ、様々な作業を混乱することなくこなせるのだ。
ノイマン型は、演算装置と記憶装置の間のやり取りを高速化できていたうちはシステム全体を高速化できた。それが近年、両者を結ぶ配線での信号伝達を高速化できなくなってきた。
通常、電子機器では素子や回路の間を金属配線でつないでいる。こうした配線には、材質や形状に応じた電気容量が存在し、一方の端からもう一方の端まで信号を伝えるのに、一定の時間が掛かる。水道の蛇口につないだ空の状態のホースに水を流すと、端から水が出てくるまでに時間が掛かるのと同じ原理だ。
ノイマン型では避けられないこの遅れが、コンピュータ全体の性能向上の足かせになっている。つまり、仕事場での作業効率がどんなに高まっても、通勤時間の長さが、こなせる仕事量を頭打ちにしているのだ。こうした性能向上の阻害要因のことを「フォン・ノイマン・ボトルネック」と呼んでいる*3」。
これは、進化が始まったばかりのAIチップの開発者にとっては、極めて大きな問題だ。自動運転車や高度なロボット、的確な診断を下す医療システム、リアルタイムでの自動翻訳機など、AIチップをさらに高性能化して実現したい応用は山積している。「ボトルネックがあるので、これ以上高性能化できません」では済まされないのだ。
人間の脳の構造を徹底的にまねる
そこで、一層の高性能化に道を開くためノイマン型に見切りをつけ、まったく新しい原理に基づくAIチップの開発を始めた企業や研究機関が複数出てきた。その代表的な企業がIBM社である。その他、Intel社、HP社とユタ大学のグループ、NECと東京大学のグループ、産業総合研究所とパナソニックのグループ、東芝、デンソー、東北大学などが研究開発に着手している。
「人間の脳の構造を見てみろ。記憶と演算が分離したノイマン型などではない。しかも、たかだか20Wのエネルギー消費で、現存するコンピュータのどれよりも高度な処理を実現している。ならば脳の構造を徹底的にまねればよいのではないか」。IBM社などが、新たな基本原理を模索する際の着眼点は、このようなものだ。
現在提案されている全てのAIチップは、程度の差はあるが、動作や構造の模範を脳の神経回路網(ニューラルネットワーク)に求めてきた。Google社のTPUは、ニューロン(神経細胞)とシナプス(神経細胞間のつながり)で構成するニューラルネットワークの構造と働きを、ノイマン型の構造上に展開しプログラムを使って再現したものだ。チップ内の演算器の仕様はAI関連処理に最適化しているが、仮想的に脳の動きをまねたチップだと言える。
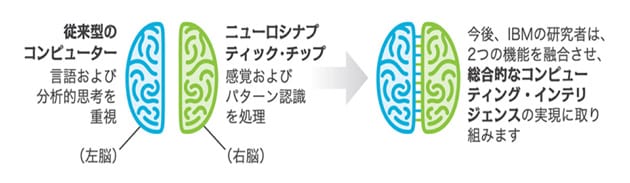
これに対し、IBM社などが目指すチップは、演算装置と記憶装置を分離せず、一体化してニューラルネットワークの物理的な構造を再現した「脳型チップ(ニューロモーフィック・チップ)」と呼ぶものだ。AIチップの進化の中では、「第2世代AIチップ」と呼ぶことができる。ただし脳型チップは、ノイマン型を使わないため汎用性を損ない、論理的な演算はできなくなっている。しかし、人間の脳も論理的な思考は左脳が、直感的な認知は右脳が担っている。IBM社では、ノイマン型ベースの従来型コンピュータと、脳型チップによるAIシステムで役割分担させることを、近未来のコンピュータの基本構成と考えている(図2)。
 |
IBM社は2014年に、世界初の脳型チップ「TrueNorth」の論文を科学雑誌「Science」で発表した。ここからは、TrueNorthに使われている技術を題材にして、脳型チップとはどのような特徴を持つ、どのような構造のチップなのかを解説していく。
あらゆる機器や設備にAIチップを組み込み可能に
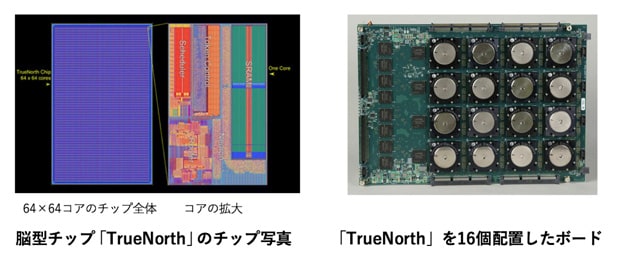
第2世代AIチップである脳型チップの先駆けになったTrueNorthは、54億のトランジスタで、100万個のニューロンと2億5600万のシナプスを作り込んだチップである(図3)。28nm プロセス*4を使って製造し、チップ面積は4.3cm2と、一般的なマイクロプロセッサと同等の大きさに収めている。
 |
人間の脳には、約1000億個のニューロンと約100兆~150兆個のシナプスがあると言われている。TrueNorthは人間の脳には遠く及ばないが、昆虫の脳と同等の規模にはなっているとされる*5。そして、「空中の小さな獲物の位置を正確に把握する」「血を吸うべき動物がいる」など、昆虫が特定の能力で極めて高度な知覚を持っているのと同様に、TrueNorthも「地震を検知して津波警報を発令する」「石油の漏れを監視する」といった特定用途に応用するのに十分な能力を実現できるようだ。
TrueNorthで特筆できる点は、1秒当たり46億回も再現されるシナプスの動きを、わずか70〜200mWという補聴器ほどの電力消費で実行できる点だ。現在AI関連処理の実行に使われるGPU*6の消費電力は数百W、第1世代AIチップであるTPUは40Wであるから、TrueNorthの省エネ度合いは際立っている。バッテリー駆動できるほどの低消費電力なので、電源供給や放熱のための回路や部品を劇的に単純化でき、AIチップの使用シーンはグンと広がる。小型ロボットや携帯型電子翻訳機、さらにはオフィスや店舗に置くあらゆる機器の中に、家電を制御するマイコン感覚で高度なAIチップを組み込むことができるのだ。
チップを並列利用して、規模を拡張
TrueNorthでは、データ処理の最小単位となるコアを、1チップに4096個実装した。それぞれのコアには、演算回路、メモリ、コア間通信用のルーターなどが含まれている。GPUや第1世代AIチップであるTPUでは、ニューラルネットワークのニューロン同士の結びつきの強さや、そこでやり取りするデータは、外部のメモリに蓄積する。これに対しTrueNorthは、演算装置と記憶装置の両方を1つのコアの中に組み込むことで、命令やデータの読み出しと書き込みをコア内で完結させているのだ。このため、フォン・ノイマン・ボトルネックを大幅に軽減できる。
それぞれのコアには、256個のニューロンと26万2144個のシナプスを再現する回路が搭載されており、各ニューロンの振る舞いを23種類のパラメータによって調整することで、単純なニューラルネットワークのモデルから、極めて複雑なモデルまで再現できるようにしている。
TrueNorth内の64×64個のコアは、256入力256出力の2次元メッシュの配線上に配置している(図4)。そして、コア内のルーター機能を使って、コア間で信号をやり取りするのだ。さらに、このチップをボードに並べることで、ニューラルネットワークの規模をさらに拡大し、より複雑な処理の実行や精度の向上を図ることができる。IBM社は既に16個のチップを1枚のボードに並べ、約1600万個のニューロンと約41億個のシナプスを備えたシステムを試作済みだが、このシステムの規模はカエルの脳に相当するという。さらに、そのボードを3枚つなげて、約4800万個のニューロン、約123億個のシナプスを持つ、ネズミの脳に相当する規模のシステムも試作したそうだ。
 |
さらなる低消費電力化へのもう1つの工夫
TrueNorthにはノイマン型をやめた以外に、もうひとつ脳神経回路の働きを模した特徴がある。「イベント駆動型回路」と呼ばれる電子回路の動作方式の採用である。その仕組みと特徴は以下のようなものだ(図5)。
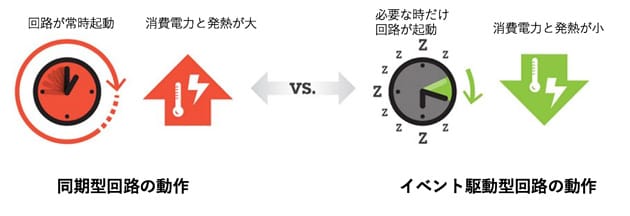 |
電子回路の多くは、「同期型回路」と呼ばれる仕組みで動いている。複雑な手順で処理する大きな電子回路を小さな回路に分轄し、それぞれをクロック信号と呼ぶメトロノームのように動きのリズムを指揮する信号に合わせて、順番にバケツリレー方式で処理していく。パソコンのCPUの性能を示す2GHzといった数字は、そのリズムの周波数を表しており、2GHzなら1秒間に20億回バケツリレーしていることを示している。
この仕組みには、安定した品質の電子回路を設計しやすいという利点もあるが、その一方で全ての回路がいつも起動しており、さらにチップの隅々までクロック信号を行き渡らせる必要があるため、消費電力が大きくなりがちだ。
これに対し、イベント駆動型回路では、信号が入力された回路だけが起動して、処理を実行する。つまり、必要な回路だけが動き、クロック信号用の配線も不要なため、消費電力を大幅に削減できるわけだ。また、ニューラルネットワークでは、隣接するニューロンに信号が入り、そこが活性化(発火)したことを合図に、周囲のニューロンの発火を呼び起こす。イベント駆動型回路の動作は、こうしたニューラルネットワークの動きに近いと言える。
ただし実際には、TrueNorthでは1kHz(1秒間に1000回)という極めて低速なクロック信号を流している。低速ながらクロック信号を利用している理由は、チップ外部の電子回路は同期型回路であり、画像、音声、センサなどからデータを入力し、チップから推論結果をタイミングよく出力するからだ。視覚情報などを脳が処理する時間は約1m秒と言われており、1kHzの1サイクル分の周期がそれと同じになるようにしている。
IBM社は、米国防高等研究計画局(DARPA)からの5350万米ドルの資金提供によって実施している「SyNAPSEプロジェクト」の中でTrueNorthを開発している。同プロジェクトでは長期的なゴールとして、100億個のニューロン、100兆個のシナプスを有する規模のシステムを、消費電力1000W、体積2リットル以下で実現する目標を掲げている。規模も消費電力の効率も人間と同等とまではいかないが、背中がかすかに見える目標値だ。同社によると、この目標を実現することで、TrueNorthを公衆安全、視覚障害者向けの視覚アシスト、健康モニタリング、自動運転などに応用できるようになるという。
不揮発性メモリで、もう一段の飛躍
脳型チップは新しいコンセプトの半導体チップであり、技術的な伸びしろはまだ十分ある。現在は、多くの企業や大学、研究機関が、様々なアイデアを投入して、さらなる高性能化や低消費電力化に取り組んでいるところだ。
特に研究開発の事例が増えているのが、脳型チップ内の記憶装置となるメモリの不揮発化である。TrueNorthは、学習結果を反映したニューラルネットワークを記憶するメモリにSRAMを使っている。SRAMは電源をオフ状態にすると記憶が消えてしまうため、利用している間は、常時電源を供給する必要があった。これを、電源を切っても記憶が消えない不揮発性メモリに替えることで、さらなる低消費電力化が実現する。
ユタ大学とHewlett-Packard社が共同開発している脳型チップ「ISAAC」では、メモリに抵抗変化型メモリ(ReRAM*7)を採用する。また、産業技術総合研究所やパナソニックセミコンダクターソリューションズなども、ReRAMを採用した脳型チップの実現を目指す。一方、IBM社は、メモリ素子の材料の相*8が変化することで抵抗値が変動する相変化型メモリ(PCM*9)の活用を検討している(図6)。
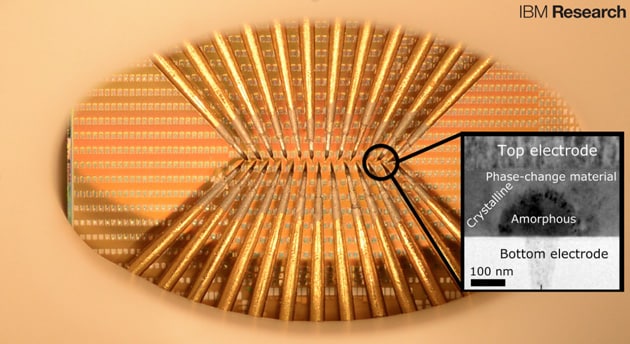 |
学習機能の組み込みも視野に
不揮発性メモリの採用は、現在の脳型チップの最大の課題の解決策になる可能性も秘めている。その課題とは、学習機能の搭載だ。AI関連処理には、データから処理方法を学ぶ学習処理と、学習した結果に基づいて入力したデータを分類したり傾向を抽出したりする推論処理があるが、TrueNorthは推論処理だけしか実行できない。あらかじめGPUなどを使って学習しておいた学習済みパラメータをチップに移植して、推論処理を実行する。しかしこの方法では、チップを搭載している機器での学習ができないため、利用シーンが限定されてしまう。
ReRAMを使うチップも、PCMを使うチップも、外部からパルス(信号)を繰り返し受け取ることで、メモリ素子の抵抗値が変化する特性を活用している。材料や素子構造を最適化することで抵抗値を連続的に変化させ、これを学習の習熟度として活用するための技術開発が進められているのだ。TrueNorthでは、シナプスのつながりの強さをデジタル値で記憶しているが、これをアナログ値である抵抗値の違いで表現できれば、メモリ素子を流れる電流値でアナログ回路的に積和演算を実行できるようになるという発想である。この構造や原理は脳内のニューラルネットワークと似ており、記憶と演算が一体化した構造になるため、実現すればノイマン型から完全に決別できる。
さらに、ほとんどパルスを加えなければ抵抗値の変動が小さく、頻繁に加われば大きく変動するようにできれば、これを学習に利用可能となる。推論処理を実行する脳型チップ自体に学習処理機能を付加できるため、利用シーンが広がるのだ。ただし、採用するメモリの材料に応じて、抵抗値の変化特性に合った学習アルゴリズムなどを開発する必要があり、技術的なハードルは高い。
究極のメモリ素子で記憶と演算を一体化
東北大学国際集積エレクトロニクス研究センター(CIES)は、ノイマン型ベースのAIチップにも、脳型チップにも適用できる、低消費電力化に向く不揮発性メモリ技術を開発した(図7)。磁気トンネル接合(MTJ*10)素子と呼ばれる、1ビットのデータだけを記憶する極小ハードディスクのようなメモリ素子を、AIチップの記憶装置として利用する技術である。
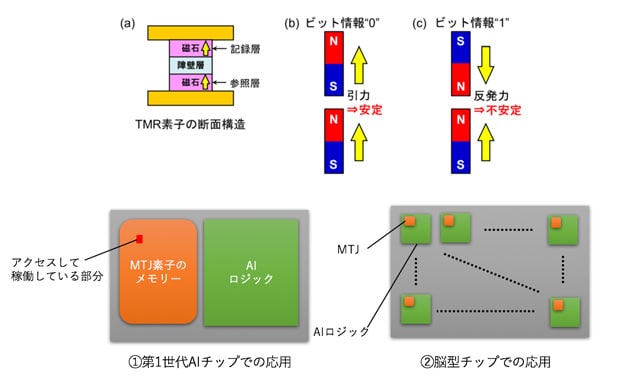 |
MTJ素子は、同じ不揮発性のフラッシュメモリや抵抗変化型、相変化型などと比較して、読み出し/書き込み速度、最大書き換え回数、演算器を構成するCMOS回路との整合性などの面で優れている。0.5n~10n秒と高速な書き込み速度は、学習内容をアップデートする時間の短縮や、エッジ側に学習機能を組み込む上で有利になる。抵抗変化型の106回よりも9ケタも高い1015回の最大書き換え回数は、学習回数の上限を引き上げ、より的確な判断を下すAIチップを育てるのに向く。さらに0.3~0.4Vと低電圧でデータを書き込めるため、ロジック回路と混載利用しても昇圧せずに利用できる。
また同大学は、記憶装置をMJT素子で構成したノイマン型ベースのAIチップを試作し(図7下段の①)、記憶装置の中でアクセスする部分だけを起動させることも可能にした。これにより、搭載した全MJT素子のうち0.05%のみを起動させ、画像認識処理をわずか600μWで実行できることを確認している。さらに、演算装置のすぐ横に記憶装置となるMTJ素子を分散配置した脳型チップも試作し(図7下段の②)、第1世代のAIチップよりも3ケタ高い電力効率、2ケタ高い集積度を実現できることを実証した。
AIチップの進化は、まだ始まったばかりだ。おそらく今後数十年掛けて、段階的に高度化していくことだろう。脳型チップについては、現状では人間の脳の構造や動作原理が完全には解明されていないため、汎用性を損なうかたちでしか実現できていない。しかし、IoTシステムや自動運転車などの技術が発展するか否かは、AIチップの進化に掛かっているのだ。
[ 脚注 ]
- *1ノイマン型アーキテクチャ
- ノイマン型アーキテクチャでは、汎用計算機を、「演算装置」「記憶装置」「制御装置」「入力装置」「出力装置」の5つの機能と、これらの間をつなぐデータ伝送機構で構成する。ノイマン型以前のコンピュータは演算器を配線でつないで計算手順を指定していたため、演算手順を変える度に配線し直す必要があった。これに対しノイマン型は、演算の手順を記したプログラムを記憶装置に格納し、プログラム内の命令を上から順に読み出し、演算装置で実行していく。プログラムの書き換えが容易なので、簡単に演算手順を変更できる。世界最初のノイマン型コンピュータは1949年に英国で開発された「EDSAC」である。現在ノイマン型と呼ばれている構造のアイデアは、ENIACの開発者であるジョン・モークリーとジョン・エッカートによるものというのが事実のようだ。しかし、開発プロジェクト顧問の立場で参加していたノイマンの名前で報告書が執筆されたことから、ノイマン型と呼ばれるようになった。
- *2TPU
- TPUとはTensor Processing Unitの略で、Google社が開発したAI関連処理、特に推論処理の高速化に特化して設計されたAIチップの名称。
- *3
- ノイマン型でも、演算を並列実行すれば高性能化は可能だ。ただし、並列化を推し進めることは、汎用性を損なうことにつながる。本連載でこれまで解説したように、AI関連処理は並列化しやすい処理が多いため、AIチップの高性能化にフォン・ノイマン・ボトルネックは大きな影響を与えないようにも見える。しかし、並列化にだけ頼った高性能化は、素子や配線の数の増大を招いて小型化と低消費電力化が難しくなり、利用シーンが限定されてくる。
- *428nmプロセス
- 半導体チップに搭載される微細なトランジスタの最小線幅が28nmとなるチップを作る製造技術を、28nmプロセスと呼ぶ。この最小線幅が小さいほど、高速で、大規模な回路を搭載したチップを作ることができる。現在、既に10nmプロセスのチップが実用化され、パソコンやスマートフォン向けに投入されている。Google社のTPUはそれよりも古い世代の技術を使っており、裏を返せばまだまだ進化する余地が十分あると言える。
- *5
- TrueNorthの開発以前、IBM社は2011年に256個のニューロン、6万4000個もしくは25万6000個のシナプスを備えたチップを試作している。この試作チップの規模は、ミミズの脳に相当していたという。
- *6GPU
- GPUとは、GraphicsProcessingUnitの略。グラフィックス処理や画像処理に特化した、専用の演算器と内部構造を持つプロセッサ。マイクロプロセッサのように、様々な命令を効率よく処理することはできないが、大量のデータを対象にして同じ演算を同時実行する並列処理に向いた内部構成を取っている。近年では、その優れた演算能力を生かして、科学計算などに活用するようにもなってきた。こうしたGPUの利用法を特に「GP(General Purpose)GPU」と呼んでいる。
- *7ReRAM
- Resistive Random Access Memoryの略。電圧の印加によって電気抵抗の変化を利用した半導体メモリのことを指す。
- *8相
- 相とは、液体、固体、結晶構造といった物質の状態を指す。相が変わると、様々な物理特性が変化する。
- *9PCM
- Phase Change Random Access Memoryの略。結晶相は低抵抗で、結晶構造が崩れたアモルファス相は高抵抗になることを利用した半導体メモリ。
- *10DLU
- Magnetic Tunnel Junctionの略。MTJ素子は、磁性層/障壁層/磁性層の 3層を基本構造とし、それぞれの厚さが数nm以下の極めて薄い層によって形成された微小なメモリ素子。2つの磁性層の磁化が互いに平行のときMTJ 素子の抵抗は低くなり、反平行のとき抵抗が高くなる。電流の印加により、片側の磁性層中にある原子のスピン方向を変えて、磁性を反転させる。
- Writer
-
伊藤 元昭(いとう もとあき)
-
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。
- URL: http://www.enlight-inc.co.jp/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
