JavaScriptが無効になっています。
このWebサイトの全ての機能を利用するためにはJavaScriptを有効にする必要があります。
- Science Report
- サイエンス リポート
半導体産業発展を支える「ムーアの法則」の過去・現在・未来
- 文/服部 毅
- 2021.06.02

過去半世紀以上にわたり、半導体産業の発展をけん引してきた経験則が「ムーアの法則」である。半導体はムーアの法則に沿う高集積化と低コスト化(集積回路に搭載されたトランジスタ1個あたりのコストの低下)によって目覚しい発展を遂げ、それを搭載した電子機器やそれを利用した社会の姿を大きく変えてきた。そしてムーアの法則は半導体製造装置、材料、デバイス、電子機器メーカー、サービスプロバイダーといった産業界の関係者が暗黙のうちに予定調和を図るための「絶対的な拠り所」として機能してきた。
経済的・技術的・物理的などの要因からムーアの法則の限界が今まで何度も繰り返し叫ばれてきたにも拘わらず、ムーアの法則はしぶとく生き続けてきた。最近も「いよいよ終焉か」と言われたが、究極のリソグラフィと言われるEUVリソグラフィがついに実用化し、さらに延命している。それでも、原子はそれ以上微細化できないので2次元での微細化はいずれ限界に達するだろうが、一部の集積回路は3次元化することで集積度を増し続けている。将来、3次元化も高層ビル同様に強度的限界に達し、よほどの奇策でも登場しない限り、ムーアの法則は終焉するかもしれない。しかし、終焉したとしても半導体産業はムーアの法則の呪縛から解放されて、自由な発想によって未来に向けてさらに発展し続けるだろう。
本稿では、このような流れに沿って、ムーアの法則の誕生からムーアの法則終焉後の世界までを解説する。
ムーアの法則の原典を読み解く
まずは、ムーアの法則とは何か、原典に当たって正しく理解しよう。
集積回路の発明者として知られるロバート・ノイス氏とともにIntel(アメリカ)を1968年に創業したゴードン・ムーア氏(図1)は、前身のFairchild Semiconductor(アメリカ)で集積回路の研究開発担当ディレクターだった1965年に、電子技術の専門誌*1へ寄稿を依頼された。そこで彼は、まだ発売されて3年しか経っておらず知名度の低い集積回路を拡販宣伝する立場にあったので、「Cramming more components onto integrated circuits(集積回路にもっと多くのコンポーネントを詰め込む)」と題する記事を書いた(図2)。彼は、後年、IntelのCEOになり、同社はいわばムーアの法則の守護神となったから、Intel時代に提案したと多くの人は誤解しているが、東海岸にあったFairchild Camera and Instruments(アメリカ)の半導体部門であるFairchild Semiconductor時代の「作品」である(図2)。
ムーア氏は、この記事に2枚のグラフを載せて、発売間もない集積回路について、部品搭載数が今後飛躍的に増大する将来有望な電子デバイスであることを説明しようとした。

- [図1] ゴードン・ムーア氏
- 出典:Intelプレスキット

- [図2] ゴードン・ムーア氏が執筆した、のちに「ムーアの法則」と呼ばれるようになる経験側を書いた記事のタイトル・リード文・著者名・所属先
- リード文の内容は「集積回路に搭載される部品点数が増えるにつれて部品ごとのコストは低下し、単一のシリコンチップ上に65,000もの部品が搭載されるようになるかもしれない」というもの。
出典:Intelニュースルーム
集積度は毎年2倍に増え続ける
その記事の要旨は次のようなものであった。
「集積回路に搭載された部品1個あたりの製造コストが最小になるような集積回路の複雑さは、毎年およそ2倍の割合で増大してきた。短期的には、この増加率が上昇しないまでも、現状を維持することは確実である。長期的には、増加率はやや不確実であるとはいえ、少なくとも今後10年間ほぼ一定の率を保てるだろう。1975年までには、最小コストで得られる集積回路の搭載部品数は65,000にも達するであろう」との予測を述べ、「それほどにも大規模な回路が1個のウェーハ上に構築できるようになると信じている」と希望的観測で締めくくった。
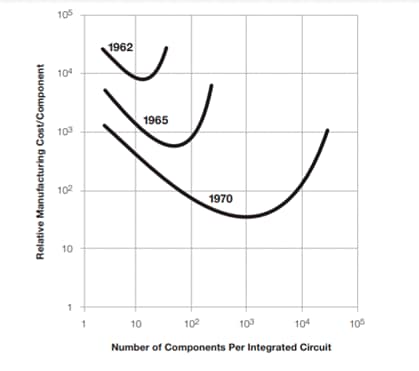
- [図3] それぞれの年に集積回路に搭載された電子部品当たりの製造コスト(縦軸:相対値)と集積回路に搭載された電子部品の数(横軸)の関係を示す両対数グラフ
- 出典:Intelニュースルーム
ムーア氏は、集積回路に搭載され電子部品1個当たりの製造コストが最小になるような最適部品点数が存在し、これが技術の進歩により毎年増えていくと予測した。電子部品を詰め込みすぎて集積度を上げすぎると欠陥数が増えて製造歩留まり(良品率)が下がってしまい、電子部品1個当たりのコストが上がってしまう。逆に電子部品数が少なすぎても1個当たりのコストは上がってしまう。彼がもっとも言いたかったことは、集積回路の製造コストを最小化する集積回路搭載部品点数は、技術の進歩とともに、つまり時代とともに、急速に増えていくだろうということだった。
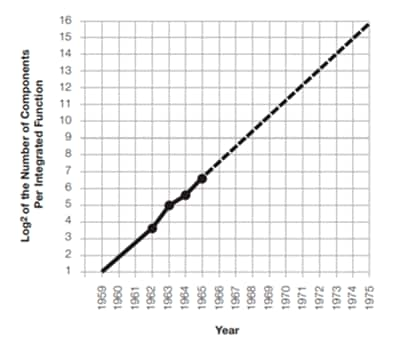
- [図4] それぞれの年に集積回路に搭載されていた電子部品数(点線は予測)
- 出典:Intelニュースルーム
図4は「ムーアの法則」を提唱する元になった有名な片対数グラフである。ムーア氏は、1965年にFairchild Semiconductorで製造し発売してきた、たった4種類のICの搭載部品数をプロットした。いずれも図3で説明したコストミニマムの電子部品数を搭載した商用集積回路である。
ムーア氏は、わずか4点から得られた片対数グラフの直線を大胆にも10年先の1975年まで外挿した。この直線は、「集積回路の搭載部品点数は、毎年倍増する」ということを意味する。これが、後年「ムーアの法則」と呼ばれる経験則である。理論的根拠があるわけではなく、集積回路がこの世に登場してからわずか3年間の経験から得られた予測に過ぎなかった。
ムーア氏の回顧談によると、10年先まで直線を外挿した理由は、雑誌の編集部から10年後の電子産業を予測するように言われたからであり、自信を持って10年後を予測したわけではないようだ。なぜこんな大胆な予測をしたのだろうか。
当時は、まだディスクリート(個別)トランジスタ全盛の時代で、どんな電子回路も高価な集積回路を使わずディスクリートだけで構成できたので、民生用にコスト高の集積回路はいらないという風潮が蔓延しており、集積回路はコストを気にしない軍事向けなどの一部の用途に留まっていた。このため、Fairchild Semiconductorは集積回路を宣伝し拡販しなければならず、半導体は将来有望ということを宣伝するために、この記事を書いたのであって、予測にそれほど自信はなかったとムーア氏は後年回顧している。
彼は、記事の最後に予測をさらに発展させ、集積度向上による電子部品1個当たりのコスト低減によって電子機器のコストは大きく低下するので「社会全体であまねく利用可能になるだろう」と述べている。また、具体的な集積回路応用例として「家庭用コンピュータ、または少なくとも中央コンピュータに接続された端末、自動車の自動制御、および個人用携帯通信機器」を挙げ、夢でしかなかった手に載るサイズの家庭用コンピュータの売り場に人だかりができている漫画が添えられていた。当時は、各企業にメインフレームと称する大型コンピュータが一台しかなく、半導体メモリが登場する以前の時代である。今から半世紀以上前に、パソコンや自動運転車やスマートフォンの登場を予想していたかのような記述を残しており、彼の先見性には今読み返してもびっくりする。
集積度は2年で倍増に修正
ムーア氏は、この記事を執筆した10年後の1975年末に、集積回路の過去10年の集積密度の推移を調べ直して「今後、半導体の集積度は2年ごとに2倍になる」と修正した。その後、この予測を皆が「ムーアの法則」と呼ぶようになり、半導体のみならず電子産業界の関係者にとっての絶対的な拠り所となった。この経験則は、一般には「半導体の集積度は、18~24か月(1年半ないしは2年)で倍増する」という表現で知れ渡っているが、ムーア氏自身は18か月と言った覚えはないと語っている。IntelのMPUの性能が18か月で倍増してきたため、それと混同されたのではないか。また、1970年以来4半世紀にわたり「3年で4倍」の割合で増加してきたDRAM(Dynamic Random Access Memory)の記憶容量の成長率が「1.5年(18か月)で2倍」に相当するところから、メモリビジネス従事者が好んで「18か月で2倍」という表現を使ってきた経緯もある。
50年余りにわたり生きてきたムーアの法則
そんなムーアの法則は2015年に「提唱50周年」を迎えた。この50年間、半導体はムーアの法則に沿う微細化・高集積化・低コスト化によって目覚しい発展を遂げ、ムーア氏が予測した通りに、それを利用した電子機器のおかげで快適な生活や効率的なビジネスが現実のものになった。
ムーアの法則を提案した当時は、集積度を集積回路に搭載された抵抗なども含むすべての電子部品で部品点数を定義していたが、集積度が上がるにつれてトランジスタが電子部品のほとんどを占めるようになったため、いつしかムーアの法則は集積回路に搭載されたトランジスタ数で定義されるようになった。
集積回路は、最初の40年ほどはMOSトランジスタのゲート幅や回路線幅を微細化することで、集積度を上げてきた。微細化が困難になるたびに、「ムーアの法則は破たんした」、「ムーアの法則は終焉した」参考資料1と何度も言われながらも、その後、今世紀に入り、トランジスタの構造や構成材料を大幅に変更し、性能を改善するというイノベーションにより、この法則は生き延びてきた。
ムーアの法則の延命をもたらしてくれたトランジスタ構造や材料変更の例をいくつか示そう。集積回路の発明以来用いられてきたプレーナー構造*2はFinFET構造*3に代わり、ソースドレイン間のリーク電流を抑制でき、電流駆動能力が向上した。絶縁膜/ゲート材料も従来のSiO2/SiN(窒化シリコン絶縁膜)/poly Si(多結晶シリコン)ゲートからHigh-k(高比誘電率絶縁膜)/メタルゲートに代わり、ゲートリーク電流が抑制された。配線材料も従来のAlから電気伝導率の高いCuに代わり、今後はCoやRuも使われるようになる。微細加工技術の要であるリソグラフィは、g線(436nm)→i線(365nm)→KrF(248nm)→ArF(193nm)と使用する光源の波長を短くすることで解像度を上げてきた。さらに、ArFエキシマレーザを光源とし、レンズとウェーハの間の液浸用液体として水を用いたArF液浸リソグラフィの導入で解像度が上昇した。その後、多くの人に実現不可能と思われていた軟X線を利用したEUV(極端紫外線、3.5nm)リソグラフィが実用化し、7nm以降のロジックでデバイス微細化の道が開け、ムーアの法則はさらに延命が確実となった。今年からは先端DRAM(10nm級の第4世代である1α-nm製品)にも適用され、用途が広がる見込みである。
過去50年余り半導体デバイスがムーアの法則にどのように従ってトランジスタ数を増加させてきたか概観しておこう(図5)。
アメリカの半導体市場調査会社IC Insightsの調査によれば参考資料2、一部の製品カテゴリの成長率はやや低下しているとは言うものの、後述するように一部のデバイスでは3次元化も始まっており参考資料3、チップあたりのトランジスタ搭載数の「2年で2倍の増加ペース」は現在も概ね継続しており、半導体業界が引き続き従うに足るガイドラインとなっている参考資料2。
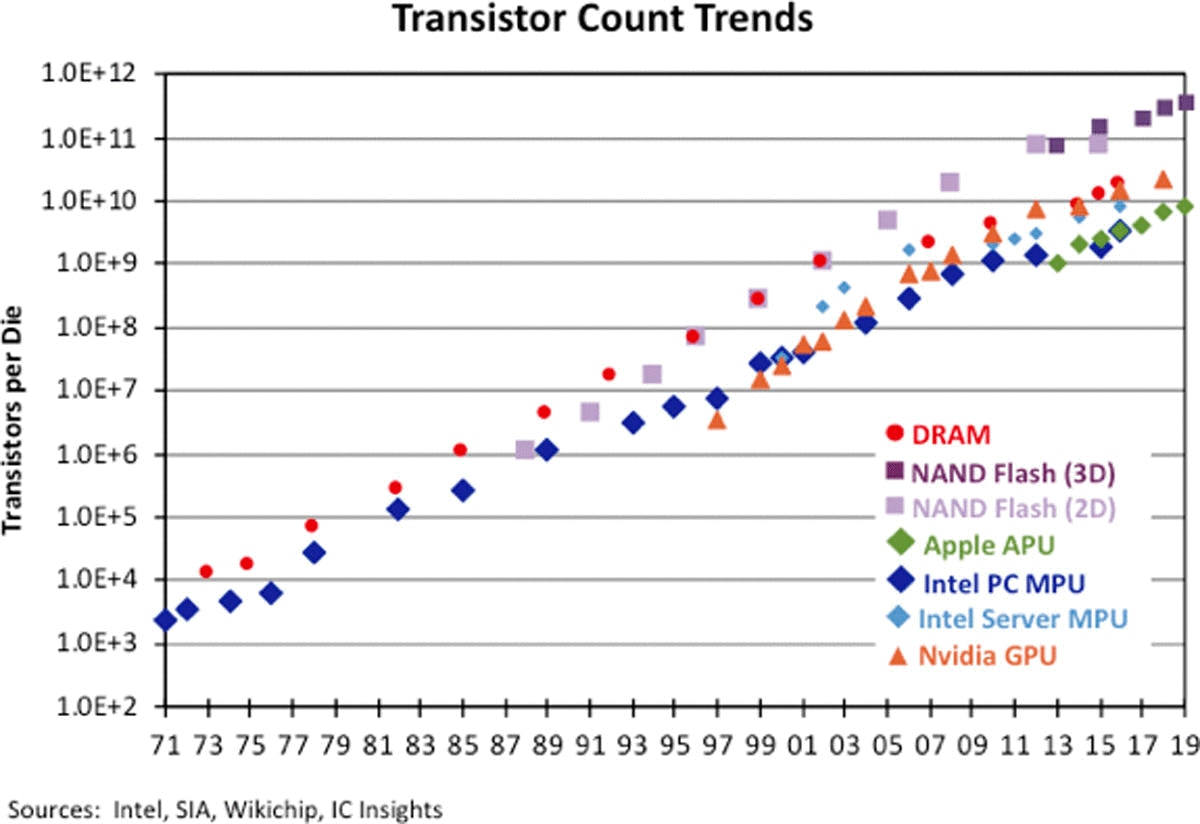
- [図5] 半導体デバイスタイプごとの半導体チップ上に搭載されるトランジスタ数の変遷
- 出典:IC Insights
NANDフラッシュメモリ容量の年間成長率は、2012年頃まで年間55〜60%であったが、その後は年間30〜35%程度となった。2次元構造の微細化は20nmかそれをやや切るあたりでやめて、後述するように、NANDは、ほかのデバイスに先駆けて3次元化することで容量増大の勢いを復活させている。すでに先端では128層から176層立体構造へと高層化が進んでいる。
DRAMに搭載するトランジスタ数は、2000年代初頭までは年間平均約45%の勢いで増加していたが、その後2016年に登場した16Gビット世代までの間に約20%に低下していた。DRAMのメモリ容量増加への要求が以前ほどなくなったこともその一因である。微細化は20nmを切るあたりで終焉かと思われていた時期もあったが、救世主のように現れたEUVリソグラフィにより、いよいよ今年からは、ロジックに続きDRAMにもEUVリソグラフィが適用され1α-nm*4の生産が始まる。
IntelのPC用マイクロプロセッサ(MPU)のトランジスタ搭載数は、2010年までは年平均約40%の増加で推移してきた。その後、その割合は半減している。Intelのサーバ向けMPUのトランジスタ数の伸びは、2000年代半ばから後半に一時的に止まったものの、その後、約25%/年の割合で再び増加し始めている。なお、Intelは、10nm以降の微細化開発でたびたびつまずき、先端CPUは一部をTSMC(台湾)に製造委託することを決めた。同社は3次元化で集積密度を上げる方向で実装技術に注力している。
iPhoneおよびiPadで使用されているApple(アメリカ)のAシリーズアプリケーションプロセッサ(APU)のトランジスタ数は、2013年以降、85億個のトランジスタを搭載したA13プロセッサまで43%/年の割合で増加をつづけており、微細化に関して世界のトップランナーである。
NVIDIA(アメリカ)のハイエンドGPUは他社のプロセッサに比べて多くのトランジスタを搭載して、すでに500億個を超えており、ムーアの法則に従い集積度を上げている。
なお、IC Insightsは、今回の分析結果を踏まえて「技術の障壁を越えて革新を目指す半導体産業の推進力としてムーアの法則は今後も決して過小評価することはできない。ICの設計および製造方法に関して、いくつかの非常に劇的な変化が進行中であることは事実であり、将来の世代に向けた性能向上を妨げる障害のいくつかは、ハードルというよりも高い壁のように見えるのも事実。しかし、半導体業界は、そうした壁を乗り越えてムーアの法則を維持し続けるだろう」と述べている参考資料2。
微細化競争で生き残ったのは3社だけ
微細化の観点から半導体企業の動向を見ておこう。回路パターンの微細化が進むにつれて、プロセス開発費用や設備投資費用が高騰してきたため、微細化競争から脱落する半導体企業が次々と出てきた。2002/2003年頃、130nmデバイスを製造できる半導体企業は世界中に26社あったが、90nmでは18社、45nmでは14社という具合に徐々に微細化競争を続ける企業が減少し、10nm以降は、Intel、Samsung(韓国)、TSMCの3社に絞られた。7nmプロセス*5では、IntelとSamsungがEUV露光を含む先端プロセスで製造歩留まりが長期にわたり低迷してきたようで、Samsungが一歩先行して先端ファブレスからの受託生産を独り占めしていると業界関係者は見ている。
日本企業は、そのほとんどが45/40nmで微細化をやめてしまい、最後まで微細化を進めていたパナソニックも28nm以降は性能が上がらないから微細化は意味がないと判断した参考資料3。トランジスタの構造や構成材料が従来のままならこの考えは正しかったかもしれないが、その後、トランジスタの構成材料がすっかり変わり、構造も変わり、さらに最近では、一部で実用化は不可能と言われていたEUVリソグラフィが実用化して露光装置の解像度が劇的に向上したため、さらなる微細化の道が開けている。
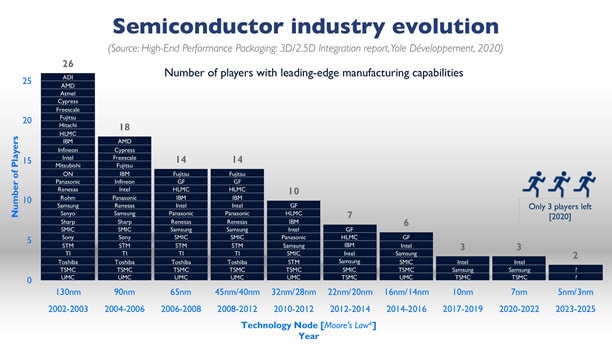
- [図6] 半導体微細化の世代ごとに生き残る企業の変遷(企業名はABC順)
- 出典:フランス半導体市場調査会社Yole Développement
今後も、トランジスタ構造はFinFETから、チャネル領域をゲートで囲んだGate-All-Aroundに進化し、リーク電流が抑制され、ゲートの電流駆動力が増す。チャネル部分はシリコンや歪シリコンに代わって、シリコン上に選択エピタキシャル成長させたGeやIII-V族化合物が採用される。これらのチャネル材料はシリコン溶離もキャリア移動度が大きくトランジスタの高速動作が可能となる。従来のNA=0.33のEUV露光装置に対し、さらに解像度を上げたN=0.55の高NA EUV露光装置が実用化に向けて開発が進んでいる参考資料4。
高NA EUVと2D材料の登場で、ムーアの法則は1nm以降も継続へ
さらには1nmプロセスでのトランジスタのチャンネル材料として2次元材料が研究されている参考資料5。グラフェンや遷移金属ジカルコゲニドなどの2次元2D)原子層状無機ナノ材料である。ベルギーの先端半導体研究機関imecは、これらの新技術・材料により、ムーアの法則が1nm以降も継続する目処が立ったとしている参考資料4 参考資料5。
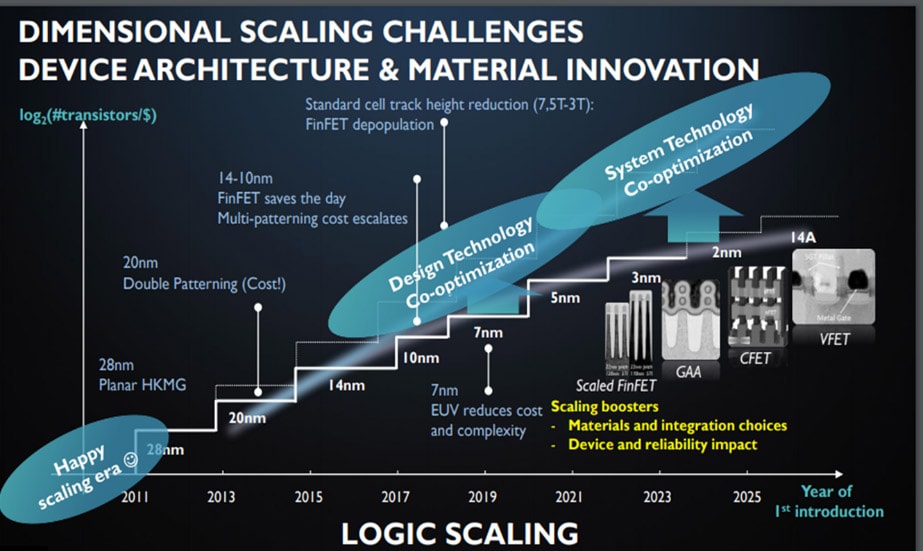
- [図7] imecの半導体ロジックデバイス微細化のロードマップ
- 出典:imec
図7は、ロジックデバイス微細化に関するimecのロードマップである。縦軸は製造コスト1ドルあたりのトランジスタ数、横軸は西暦(年)である。28nmぐらいまでは従来構造を比例縮小するだけでムーアの法則通りに集積化が実現していたが、その後もムーアの法則を延命させるには、IC設計とプロセス技術の同時最適化、さらにはプロセス技術とIC設計及びシステム設計の3者の同時最適化を実現する手法を編み出さねばならないと主張している。imecを始め半導体メーカーでは、これらの同時最適化手法により、ムーアの法則の延命を図りつつある。
しかし、“Atoms cannot scale(原子はそれ以上縮小できない)”と言われる段階になれば、いずれ物理的限界は来るだろう。でも、そんな先のことは現段階では誰にも分からない。分子や原子にメモリ効果やトランジスタ効果を持たせようと破壊的研究をしている人たちもいる。
2D微細化から3D積層化へ向けた「ムーアの法則2.0」
ムーアの法則は微細化に関する法則と誤解している人が多いが、集積化(集積回路に搭載するトランジスタ数)に関する法則である。もちろん微細化すれば単位体積当たりの集積度が増すから集積度を増す有力な手法であることは間違いない。平面的な微細化が無理になったからと言ってムーアの法則は終焉しない。3次元に積み上げれば、単位面積当たりの集積度は上がり、ムーアの法則はさらに延命する。集積度を今後は垂直方向に高めるわけだ。このように3D化による高集積化を「ムーアの法則2.0」と呼ぶ人もいる。
3次元実装は、ロジックよりもメモリの方が先に実用化段階に入っている参考資料6。3次元化へといち早く舵を切ったのが、NANDフラッシュメモリである。各社とも現在量産中の20~15nm*6世代で微細化に見切りをつけ、メモリセルを3次元積層してチップ面積当たりのビット密度を高める方向へシフトしている。いわゆる「3D(3次元)NAND」だ。
3D NANDのコンセプトを、業界に先駆けて2007年に提唱したのが東芝である。多段積層した膜の上段から下段までを貫くエッチングプロセスを使い、多段のメモリセルを一括で形成する。メモリセルを1段ずつ形成する方法に比べてコストを大幅に下げられる。
量産では韓国のSamsung Electronicsが先行した。2ビット/セルの多値化技術を用いた24段積層の128Gビット品の量産化に2013年に成功した。現在は、各社が128層3D NANDの量産に力を入れ、一部では176層が製品化されている。間もなく200層を突破するだろう。
フラッシュメモリだけではなく、3D DRAMの研究も各社密かにしているようだがまだ実用化に至っていない。その代わり完成した複数枚のDRAMチップを積み重ねてSi貫通ビア(TSV)を用いて相互配線した3次元実装が実用化している参考資料6。複数のDRAMチップとコントローラ・チップを積層し,多数のTSVで接続したDRAMモジュールをハイエンドのネットワーク機器やスーパーコンピュータ向けに実用化している。
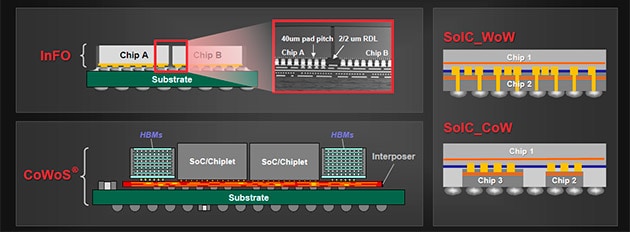
- [図8] 従来の「チップ集積」に代わる、複数のチップを基板上に搭載する「システム集積」の一例
- 出典:TSMC
ロジックデバイスに関しては、単一チップ内で集積度を増す、いわゆるチップ集積から、複数の半導体チップ、あるいは従来のSoCチップを機能ごとに分割したチップレット(Intelでの呼称はタイル)をパッケージ基板上で集積するシステム集積が主流になりつつある。基板に搭載したシリコンインターポーザ―*7上に近接してチップを並べてシステムを構成することを2.5D(2.5次元)実装と呼ぶ場合がある(図8左下、図9はその一例)。
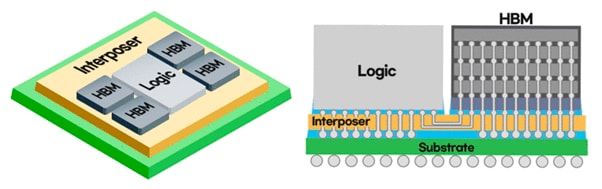
- [図9] Samsung Electronicsが2021年5月6日に提供開始した、シリコンインターポーザ―上に4個の広帯域メモリ(HBM)と1個の信号制御用ロジックチップを2.5D実装した「I-CUBE4」デバイス
- 出典:Samsung Electronics
ここで、世界中の多くのファブレスやIDMを顧客に抱えるTSMCの標準的なシステム集積手法を紹介しよう。1つ目がInFO*8(図8左上)。シリコンダイの外側にパッケージの入出力端子の領域を広げたことを特徴とする。外側の領域があることで、1000ピンを超える入出力端子を処理可能にするとともに、マルチダイの搭載を実現した。シリコンダイの入出力パッドからパッケージの入出力端子へと入出力信号を再配置する高密度な再配線層はRDL(Redistribution Layer)と呼ばれており、薄膜プロセスで形成する。
2つ目のCoWoS*9は、樹脂でできたパッケージ基板の上に、多層配線を形成したインターポーザと呼ばれる中間シリコン基板を配置し、その上に複数のシリコンダイを横に近接して並べるものである(図8左下)。
最近では、Chip-Stacking*10やWafer-Stacking*11でシステムを構築する、より難度の高いSoIC(Systems on Integrated Chips)が開発されている。SoICはさらにCoW(Chip on Wafer)とWoW(Wafer on Wafer)に細分化される(図8右)。SoIC構造では、複数の半導体チップ(あるいはウェーハ)をバンプレス相互接続でスタックでき、これにより、1つのチップからの信号を別のチップに最短距離で伝送できるようになる。10枚以上のウェーハを積層した3DICの開発も行われている。
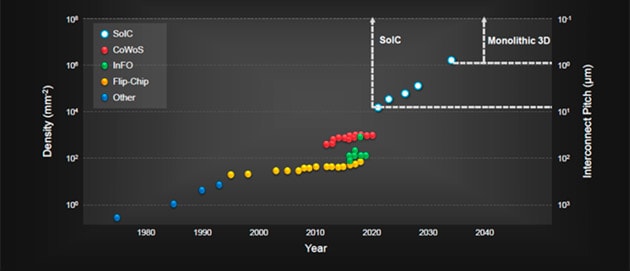
- [図10] さまざまな実装技術ごとのデバイスI/O(入出力)密度と相互配線ピッチの変遷と予測
- 出典:TSMC
図10は、TSMCにおける様々な実装技術ごとのデバイスI/O(入出力)密度と相互配線ピッチの変遷と予測である。TSMCは、2011年からCoWoSを多くのデバイスに適用してシステムの集積密度を上げてきた。今後は3DICを採用することにより複数のチップを縦に積層することでI/O密度を飛躍的に上げるとしている。究極的には、大昔から提案されてきた理想的なモノリシック3D(複数のシリコン基板を積層するのではなく、プロセス技術を駆使して一枚のシリコン基板の上にトランジスタを積層していく構造)の実現が期待されるが、実現はだいぶ先になるだろう。
ポストムーア:自由な発想で知恵を絞る新たな時代の始まり
2次元の微細化が“Atoms cannot scale”と言われる物理的限界に達し、3次元化によりチップを縦に積みあげる高集積化も強度的な限界に達すれば、奇策でもない限り、いずれ、ムーアの法則は終焉を迎える時が来るだろう。
ムーアの法則が機能しなくなり、過去半世紀以上にわたり続いてきたトレンドが崩壊するということは、力ずくでやりとげる時代から知恵を絞り独創力を発揮する非連続の時代への変化を意味する。
微細化トレンド倒壊で先が読めない不安な時代が来たと捉えるのではなく、トレンド追求の呪縛から解放された知識創造の時代の到来と捉えるならば、無限の可能性を秘めた明るい未来を拓くことも可能だろう。独創力を発揮して大胆な発想で付加価値ある新製品を世に問える時代が来るというわけだ。
もはや自由な発想を制約する指標や進化軸などは存在せず、微細化に頼らずにシステムの性能を上げる方法を考える必要がある。今までのノイマン型ではない非ノイマン型のアーキテクチャー*12など、新たな動きがすでに出てきている。
ムーアの法則が終焉したら、最も大きな影響を受けるのは半導体設計だろう。今までムーアの法則に言わばただ乗りして、製造付加価値型の製品を開発、あるいはそのためのインプリメンテ―ション設計に終始していた設計者が、設計付加価値型の製品開発を余儀なくされるようになるということである。半導体は知識創造型産業であることが明確になり、設計技術者の独創性が今まで以上に問われるようになるだろう。
持続可能な社会での快適なライフスタイルの提供が今後の技術開発の拠り所になるだろう。あえて、半導体特性に直結した指標を挙げよということならば、エネルギー節減のための超低消費電力化だろう。すべてのものをインターネットに乗せてそれをモバイルで制御する本格的なIoT時代になると、極端なまでの超低消費電力化、省エネルギー化が求められるからである。
ムーアの法則に代わるか「エネルギー効率2年で倍増の法則」
世界中の国々が脱炭素化に舵を切り、データセンターの省電力化を中心に半導体デバイスの電力効率向上がこれまで以上に求められるようになってきたが、TSMCのリュウ会長は、今後「集積回路のエネルギー効率性能スループット×スループット/消費電力)が2年で2倍になる」とISSCC2021の基調講演で述べた参考資料7。
これまで発表されてきたGPUのエネルギー効率をプロットしてみると、新たなトランジスタ構造や新材料を次々導入することにより性能に対するエネルギー効率性能を2年で2倍に高めることに成功してきている(図11)。今後も、エコシステムを形成する半導体素材メーカー、半導体製造装置メーカー、プロセス技術者、回路設計者、システムアーキテクト、それに世界中のアカデミアが協力し合うことでエネルギー効率性能は2年に2倍の割合で改善していこうとリュウ会長は関係者に呼びかけており、指標に従うのに慣れている半導体関係者にとっては、これがムーアの法則亡き後の持続可能な社会における半導体産業をけん引する指標になるかもしれない。
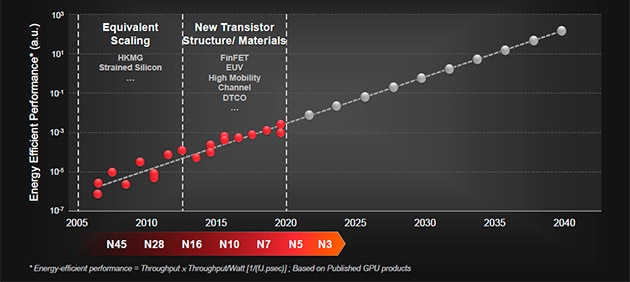
- [図11] GPUのエネルギー効率性能(スループット×スループット/消費電力)の過去の推移と今後の予測
- 注)N45などの呼称はTSMCにおける微細化技術ノード(nm)を意味する。
出典:TSMC
[ 参考資料 ]
- 1. 「さらばムーアの法則」 日経エレクトロニクス(2015年4月号 p.29-43)
- 2. 服部毅:「ムーアの法則は死なず、トランジスタ数は今も2年で2倍の増加ペースを維持」 マイナビニュースTECH+(2020年3月24日)
- https://news.mynavi.jp/article/20200324-1001886/
- 3. 「三洋電機の古池進氏、『28nm以降の微細化は意味を持たない』」 日経xTECHニュース記事(2011.5.19.)
- 前パナソニック半導体担当副社長の立場での発言、なお、パナソニックは2020年に北陸3工場を含めて半導体事業すべてを台湾勢に売却し、半導体事業から撤退してしまった。
- https://xtech.nikkei.com/dm/article/NEWS/20110519/191938/
- 4. 服部毅:「ムーアの法則は1nm以降も延命へ、imecとASMLが次世代露光技術の開発で協業」 マイナビニュースTECH+(2020.11.27.)
- https://news.mynavi.jp/article/20201127-1531857/
- 5. 服部毅;「imec、2nmフォークシートデバイスや2D材料を用いた微細FET検証結果を発表」 マイナビニュースTECH+(2020.12.16.)
- https://news.mynavi.jp/article/20191216-940012/
- 6. 服部毅:「ムーアの法則50周年 〜平面での微細化が行き詰まったら縦方向に積層へ」Telescope Magazine(2015.3.31.)
- https://www.tel.co.jp/museum/magazine/material/150327_report04_02/03.html
- 7. 服部毅:「TSMCの会長が語った3D IC技術の現状と将来展望 - ISSCC 2021」 マイナビニュースTECH+(2021.2.25.)
- https://news.mynavi.jp/article/20210225-1752851/
[ 脚注 ]
- *1 "Electronics"(1965年4月19日号)の創刊35周年特集「The experts look ahead(専門家が電子産業の将来を予測する)」
- *2 プレーナー構造:
- トランジスタ表面が平たんな構造。
- *3 FinFET構造:
- トランジスタが基板上にせりあがる構造。Intelでの呼称はTriGate。
- *4 α-nm:
- 1x-nm、1y-nm、1z-nmに次ぐ10-nm級の第4世代に相当する。15nm未満と推定されるが各社数値を公表していない。
- *5
- Intelの7nmプロセス、および性能的にはそれと同等と言われているTSMCやSamsungの5nmプロセス。
- *6
- ワード線の配線ピッチの1/2(=ハーフピッチ)の長さを指す。
- *7
- 多層配線だけで構成されたシリコンチップ。
- *8 InFO:
- Integrated Fan-Outの略で、一般には、Fan-Out Wafer-Level Packaging(FOWLP)」と呼ばれる実装方式のTSMC独自の呼び方。
- *9 CoWoS:
- Chip-on-Wafer-on-Substrate(樹脂基板の上のウェーハ、さらにその上のチップ)の略。
- *10
- チップを縦方向に積み上げる方式。
- *11
- ウェーハを縦方向に積み上げる方式。
- *12
- 演算デバイスとしてのワイヤードロジックFPGAの活用、脳型コンピュータや量子コンピュータなどを指す。
- Writer
-
服部 毅(はっとり たけし)
-
ソニー(株)に30年余り勤務し、中央研究所で半導体基礎研究、半導体事業本部でデバイス・プロセス開発から量産ラインの歩留まり向上まで広範な業務を担当。この間、本社経営/研究企画業務、米国スタンフォード大学大学院留学、同集積回路研究所客員研究員等も経験。リサーチフェロー。2007年に技術・経営コンサルタント、国際技術ジャーナリストとして独立し現在に至る。マイナビニュースTECH+、日経xTECH、セミコンポータル、週刊エコノミストに半導体産業・技術動向記事を随時掲載。工学博士。The Electrochemical Society(ECS)フェロー・終身名誉会員。主な著書に『シリコンウェーハ表面のクリーン化技術(リアライズ社)』、同英語版(Springer社)、『半導体MEMSのための超臨界流体(コロナ社)』『メガトレンド半導体2014ー2023(日経BP社)』がある(共に共著)。
- https://news.mynavi.jp/author/0001750/
新着記事
よく読まれている記事
Loading...- SHARE!
-
-
-
