- Japanese
- English
停滞の時期にある音声認識技術
しかし、冒頭でも述べたように、最近になるまで音声認識技術が主流のユーザーインターフェイスとして使われることにはならなかった。
電子技術総合研究所(現産業技術総合研究所)で音声認識の研究に取り組み、Juliusの言語モデルなどの開発に参加した、法政大学情報科学部の伊藤克亘教授は「この10年間、音声認識技術自体の進歩はほとんどありません」と語る。
それでは、Siriを始めとする音声入力インターフェイスが現在注目されるようになってきたのはなぜか。
「音声認識それ自体ではなく、コンピュータやネットワークの処理速度が向上したという外部技術の進歩が大きいと考えられます。Siriでも音声は端末上ではなく、クラウド上で処理しています。また、雑音の多い環境から人間の音声だけを抽出するといった音響技術が進歩し、スマートフォンの普及とうまくかみ合ったというのが今の状況でしょう」
Juliusの言語モデルを作成するために、伊藤教授は新聞やウェブから2億語のサンプルを抽出した。これに対して、アップルやGoogleでは、膨大なユーザー数を抱えるサービスを構築し、そこから日々得られるフィードバックを元に音響モデル、言語モデルの精度を上げていくことができる。
Siriについていえば、ユーザーに使う気を起こさせる演出がうまくなされているという面も大きいと伊藤教授は指摘する。日本ではそれほどでもないが、米国などではSiriのキャラクター(米国用は女性の声)にファンもおり、的外れな回答も笑って許される雰囲気がある。いずれにせよ、今後しばらくは、音声認識技術開発の主導権を握るのは、ビッグデータを扱える企業ということは間違いないだろう。圧倒的な「量」で「質」を作っているともいえ、大学などの研究機関では研究テーマにしづらくなっている。
現在、伊藤教授の研究室でも、研究の比重を、文字入力のためだけの音声認識から、話者認識、あるいは歌声の声質分析といった感性的な分析に移している。話者による特徴を取り出して会議などから話者を推定する、地声と裏声の使い分けを分析し歌い方のアドバイスを行うといったシステムの開発を目指しているという。
感情を持ったコンピュータを作ることはできるか?
隠れマルコフ、Nグラム法が音声認識の主流だが、こうした手法には限界もある。例えば、これらに基づいた音声認識では、文脈や話し手の感情を判断することができない。
「あなたが嫌い」
人間であれば、相手の口調から本当に嫌われているのか、あるいは照れ隠しなのかを判断することができる。しかし、感情というのは一瞬で変化するものであり、大量のデータをサンプリングしてモデル化するのが難しい。ほとんど研究が進んでいないのが現状だ。
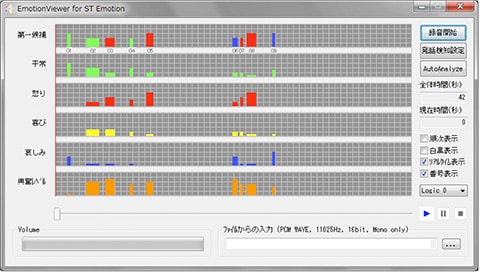
これに対して、ユニークなアプローチを行っているのが、株式会社AGI社長で、東京大学大学院工学系の非常勤講師も務める光吉俊二博士だ。光吉博士が開発した「ST」(Sensibility Technology:感性制御技術)は、声の状態から感情やストレスなどの状態を分析する技術である。
人間は、声道の形を変化させて声を出す。しかし、声帯は、情動を司る大脳視床下部と迷走神経でつながっており、話者が意識的にコントロールできない部分も大きい。この不随意な要素を音声から抽出して、脳の状態を分析しようというのがSTの基本的な考え方だ。
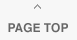
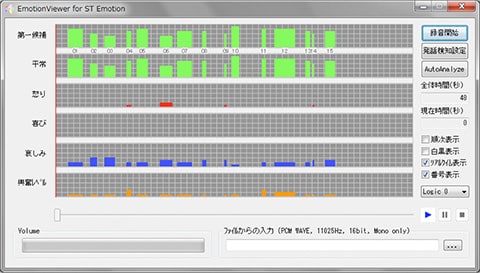
「息をのむ」という表現があるが、STではこうした呼吸やリズムの変化など、さまざまな要素をモデル化して分析に利用する。総勢2800名の被験者に(感情を含んだ)発話を行ってもらい、その音声データを聞いた100名以上のモニターが発話者の感情を判断、これらのデータを元に感情を判定する仕組みを開発した。日本語・英語といった言語に依存することなく「喜び」「怒り」「哀しみ」「平常」「笑い」といった感情の状態、および「興奮」を同時に認識でき、抑鬱状態の診断や声優の演技分析などに応用されている。認識用の辞書、周波数推定にほとんど依存しない独自の手法を採用したことで、低ビットレートの通話アプリでも感情の分析が可能になった。
 |
 |
 |
 |






-
21.3.22
タンパク質構造予測を可能にするAI

-
21.3.8
ロケットエンジンの課題を解決する「折り紙式」燃料タンク

-
21.2.22
AI顕微鏡は、数分でガン細胞を見つける

-
21.2.8
太陽エネルギーを数ヶ月から数年保存する新素材

-
21.1.26
完全にフラットな⿂眼レンズでカメラが変わる