これからの半導体技術の進化はAIチップのためにあると言っても過言ではない
アメリカで開発された黎明期のコンピュータ「ENIAC(エニアック)」は、倉庫1棟分の大きさがあり、消費電力は150kWだったという。今では、それをはるかに超えるケタ違いの性能を持ったコンピュータが、はがきよりも小さいスマートフォンの中に収められ、バッテリーで駆動できるようになった。こうしたコンピュータの高性能化、小型化、低消費電力化を実現する原動力となったのが、半導体チップの進化である。
AIシステムの機能を、小型機器中に組み込み、低い消費電力で実現できるようになれば、応用範囲は一気に拡大することだろう。実際、AIの活用を切望している応用分野は多く、AIを必要とする様々な場面で活用できる新たな半導体チップの登場が待ち望まれている。そうした要求に応える、AI活用の拡大をけん引する役割を担っているのが、AIチップなのだ。
前にも述べたようにAIチップの明確な定義はまだない。既存のGPUやFPGAも、AIチップの一種として扱われることがある。本連載では、「AIシステムの中で実行する処理を、無駄なく効果的に実行する内部構造を備えた、AIシステム専用に設計されたチップ」をAIチップと呼ぶことにしたい。
今すぐにでもAIチップを使いたい、というのがAIの応用を考えるすべての企業の総意であろう。そうしたニーズ側での渇望状態を反映して、主要な半導体メーカーはもちろんのこと、ITシステムやサービスを提供する企業も独自AIチップの開発に着手し始めている。
半導体技術は約50年にわたって進化し続け、マイクロプロセッサとメモリを高度化させてきた。次の50年間における半導体技術の進化は、AIチップの高度化のためにあると言ってもよいかもしれない。連載の第2回では、現在各社が開発しているAIチップに投入されている技術について解説する。
参考解説:ニューラルネットワーク内での演算処理
AIチップの必要性を実感するために、ニューラルネットワークを使ったAI関連の処理では、どのような演算を、どの位実行する必要があるのか、少し丁寧に解説しておきたい。AIは今後の情報システムを語るうえで重要な役割を果たすことは確実である。ただし、これまでのコンピュータとは、演算の手順や処理内容が大きく異なる。AIシステムの内部で行われている演算がどのようなものであるのか知っておくことは、様々なAIシステムやAIチップの違いを知るうえでの基礎知識になる。誰もが知っておいて、損はないだろう。
ニューラルネットワークでは、生物の神経回路網の働きを模倣した演算ルールによって、入力データの値から出力データの値を計算する。例えば、入力値として画像データの画素1つ1つの濃淡の値を入れると、出力値としてそれが「猫」であるのか「犬」であるのかといった判断結果が、確率として出力される。ニューラルネットワークでは、入力層にデータを入力してから出力層より判断結果を得るまでに、何層もの中間層を経て演算を繰り返す。この中間層が2層以上ある場合をディープラーニング(深層学習)と呼んでいる。
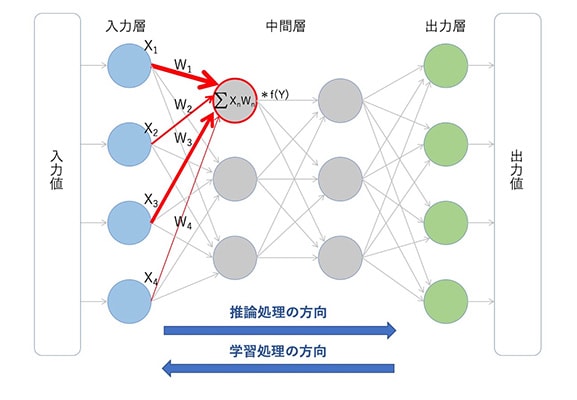
推論処理では、ニューラルネットワークの各層を構成する1つ1つのニューロン(演算素子)において、次のような計算を行う(図6)。図中の赤丸で囲んだニューロンに注目していただきたい。前層の出力データ(Xn)それぞれに、前層のニューロン間との接続(赤い矢印)それぞれの強弱を表現した重みパラメータ(Wn)を掛け算する。そして、掛け算の結果をすべて足し合わせる。次に、掛け算と足し算を終えて得た値(積和演算の値)に活性化関数と呼ぶ演算(図中ではf(Y))を施す。これは、データの値に応じたニューロンの振る舞いを表現したものだ。例えば、積和演算の値が負の場合には「0」を、正の場合にはそのまま出力するといった処理である。これが1層中の1つのニューロンでの演算の内容であり、ニューラルネットワークの階層分だけ演算を繰り返す。
 |
学習処理では、まず仮に入力層から出力層に向かって推論処理を実行する。そして、得られた判断結果と、望ましい結果を比較して誤差を求める。例えば「犬」と判断したい画像であるのに「猫」と判断できる結果が出てきたら、この差分を誤差とするのである。そして今度は、この誤差を使って、出力層から入力層に向かって演算を逆に進めていく。そしてその過程で、各層の重みパラメータを更新していく。この操作を何度も繰り返すことによって、誤差を小さくしていくわけだ。こうした学習処理を施した後の重みパラメータを移植すれば、真っさらなニューラルネットワークであっても、誤差の少ない推論処理ができるようになる。
推論処理では、繰り返す演算の回数は莫大であるものの、単純に積和演算を進めていくだけだ。このため、データの表現形式は8ビットの整数であれば十分である。これに対し、学習処理では誤差を正確に扱うことが、処理精度を高めるうえでのポイントになる。そのため、誤差を16ビットもしくは32ビットの浮動小数点で表現して扱うので、推論処理よりも学習処理の方が段違いに演算の負荷が高くなるわけだ。
Writer
伊藤 元昭(いとう もとあき)
株式会社エンライト 代表
富士通の技術者として3年間の半導体開発、日経マイクロデバイスや日経エレクトロニクス、日経BP半導体リサーチなどの記者・デスク・編集長として12年間のジャーナリスト活動、日経BP社と三菱商事の合弁シンクタンクであるテクノアソシエーツのコンサルタントとして6年間のメーカー事業支援活動、日経BP社 技術情報グループの広告部門の広告プロデューサとして4年間のマーケティング支援活動を経験。
2014年に独立して株式会社エンライトを設立した。同社では、技術の価値を、狙った相手に、的確に伝えるための方法を考え、実践する技術マーケティングに特化した支援サービスを、技術系企業を中心に提供している。










-
21.3.22
タンパク質構造予測を可能にするAI

-
21.3.8
ロケットエンジンの課題を解決する「折り紙式」燃料タンク

-
21.2.22
AI顕微鏡は、数分でガン細胞を見つける

-
21.2.8
太陽エネルギーを数ヶ月から数年保存する新素材

-
21.1.26
完全にフラットな⿂眼レンズでカメラが変わる