自分でデータ分析をすれば、データを見る目が養われる
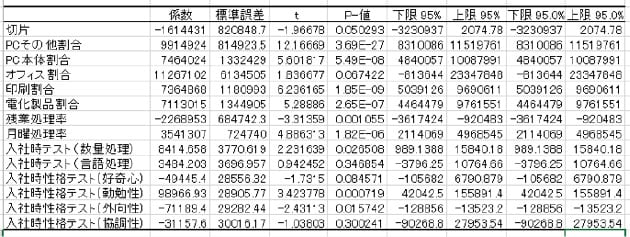
ここまでできたら、アウトカムである売上と、スタッフごとの特徴を表す説明変数との間にどんな関係があるかを、統計学の手法で計算していけばいい。といっても、計算手法についても定石があり、売上のように数値として計算できるアウトカムなら「重回帰分析」という手法を使うことになる。一般的な統計学の教科書には、いくつもの手法が紹介されているが、まずは重回帰分析だけでも多くの発見があるはずだ。重回帰分析は、アウトカムと複数の説明変数の相関関係を分析する手法だが、ユーザーはその仕組みを知らなくても、手順にしたがってExcelを操作すれば、簡単に分析できる(詳しい手順については、『1億人のための統計解析』(日経BP社)を参照してほしい)。
重回帰分析の結果を見ると、売上に影響を与えている説明変数が見えてくる。この例でいえば、残業時間中に受注処理をしているスタッフは売上が低い、特定の製品ジャンルの割合が高いスタッフほど、売上が高いといったことがわかるかもしれない。逆に、何となく関係がありそうだと思っていたスタッフの性格が、まったく売上には関係がないことがわかるである。最初から「残業を熱心にするスタッフは売上が高いか」などと仮説を立てるよりも、はるかに効率よく意味のある発見ができるようになるのだ。
このようにデータ分析を行って初めて、仮説を立てる意味が出てくる。
「残業をしていないスタッフは売上がよいようだが、残業禁止にしたら売上はどう変化するだろう?」
「新規にスタッフを採用するとしたら、どんなスキルを重視すべきだろう?」
分析結果を元に施策を行って、その結果をさらに検証していくことで、ビジネスを改善していくことができるわけだ。高度な統計学の知識やプログラミングスキルがなくても、十分に意味のある発見を行えることがわかるだろう。データサイエンティストはけっして特別な職種ではないのだ。
さらに、自分でデータ分析を実際に行い、考察を重ねていくと、ビジネスに限らずデータを見る目が養われていく。
「この製品は使用者の満足度ナンバーワンといっているけど、データの集め方がおかしくないか?」、「この政治家は、数字を出してもっともらしいことを言っているけど、本当にそうなんだろうか?」
データ分析というツールを手に入れることで、ビジネスという枠組みを超え、社会や世界の見方も変わっていくはずだ。
 |
[ 脚注 ]
- *1
- Hadoop:Apache Software Foundation(ASF)が開発・公開している、大規模データを効率的に分散処理・管理するためのソフトウェア基盤(ミドルウェア)。オープンソースソフトウェアとして公開されており、誰でも自由に使用できる。
Writer
山路 達也(やまじ たつや)
1970年生まれ。雑誌編集者を経て、フリーのライター/エディターとして独立。IT、科学、環境分野で精力的に取材・執筆活動を行っている。
著書に『Googleの72時間』(共著)、『新しい超電導入門』、『インクジェット時代がきた』(共著)、『日本発!世界を変えるエコ技術』、『弾言』(共著)など。
Twitterアカウントは、@Tats_y







-
21.3.22
タンパク質構造予測を可能にするAI

-
21.3.8
ロケットエンジンの課題を解決する「折り紙式」燃料タンク

-
21.2.22
AI顕微鏡は、数分でガン細胞を見つける

-
21.2.8
太陽エネルギーを数ヶ月から数年保存する新素材

-
21.1.26
完全にフラットな⿂眼レンズでカメラが変わる