- 中山 健夫
- 京都大学大学院
医学研究科教授
- 喜連川 優
- 国立情報学研究所所長、
東京大学生産技術研究所教授
PRESENTED BY

No.019
特集:医療ビッグデータが変える医学の常識


クロストーク ”テクノロジーの未来を紐解く
前編:ビッグデータは医療をどう変えるのか
21世紀はデータサイエンスの時代である。AIを活用しビッグデータを解析する。その結果は、これまでのサイエンスの限界を超える知見を与えてくれる可能性が高い。医療の世界も同様だ。人の健康、病気やその治療に関するビッグデータは、医療の質の向上や効率化などに大きく貢献する。では、医療ビッグデータをどのように活用すればよいのだろうか。京都大学大学院医学研究科において疫学研究に努め、日本初の医療ビッグデータ関連の書籍『医療ビッグデータがもたらす社会変革』を刊行した中山健夫氏と、国立情報学研究所所長と東京大学生産技術研究所教授を兼任する情報解析の第一人者喜連川優氏に、それぞれの立場から医療ビッグデータの可能性について語ってもらった。
 |
中山 ── 医学研究の対象は長い間、人間ではなくマウスなどの動物でした。もちろん臨床の場において医師は、目の前の患者さん、つまり人間を一生懸命に診察して治療にあたります。けれども、その同じ医師が、ひとたび病棟を離れて実験室で研究に取りかかると、今度は頭を切り替えて動物を相手にするわけです。
私が専門としている疫学*1研究は人間を対象としています。しかも多様性に富んだ人間を理解するため、個々の人間ではなく、人間集団が対象となります。ただし、ほんの20年ぐらい前までは、疫学はダーティーサイエンスと呼ばれていました。要するにピュアなサイエンスとは、さまざまなノイズをシャットアウトした環境で行うものであり、人間集団のようにノイズに満ちた対象を扱う科学はピュアとはいえないと、考えられていたのです。
その当時、対象とされていた人間集団のスケールは、数千人から多くても数万人レベルです。ところが、この10年ぐらいでデータに関する環境が激変しました。例えばレセプト*2のデータを研究に使えるようになりました。これはデータ収集におけるパラダイムシフトだったと言えるかもしれません。研究者が努力して集めていたデータが、自然に集まってくるものへと変わったのです。従来の研究におけるデータとは、研究者がまず仮説を立てた後に、病院や地域などのフィールドに出向いて、自分たちで集めてくるものでした。ところがレセプトのデータは、わざわざ集めに行かなくとも、既に存在している。以前なら想像もできなかった膨大な量のデータ、まさにビッグデータを研究に使えるようになったのが、ここ10年前ぐらいの大変化です。
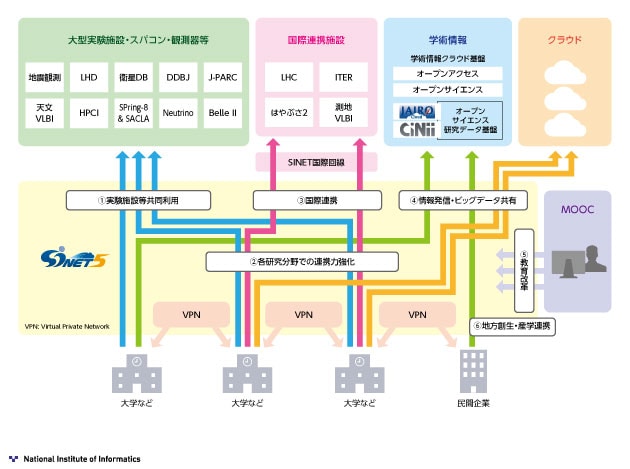
喜連川 ── センターで取り組んでいるのは、医療画像の大量収集です。膨大な量のデータの送受信には、NIIが構築・運用する「SINET5(Science Information Network)」を使います。これは全国の大学や研究所など約900の機関をつなぐ超高速通信ネットワークで、その通信速度は100Gbpsです。一般家庭の光回線が100Mbpsぐらいですから、その1000倍になります。
1000倍速いともいえるし、1000倍大きなデータを送ることができるとも考えられ、このネットワークならデータ量の大きな医療画像データもストレスなく送受信できます。
現在、医学系の学会が病院などから収集して匿名化されたデータが、SINET5を経由して「医療画像ビッグデータクラウド基盤」にどんどん送り込まれています。このクラウド基盤には医学研究者はもちろんIT系の研究者も入ることができ、NIIの管理のもと研究者たちが自由にデータを使える仕組みになっています。このような大規模なフレームワークは日本で初めてだと思います。
 |
今では放射線学会、病理学会、消化器内視鏡学会、眼科学会、皮膚科学会、超音波学会とパートナーシップを結んでおり、現時点で約1000万枚の画像データを蓄積しています。この画像を対象として機械学習や深層学習による医療画像解析を行い、病気の診断支援システムをつくることが我々の課題です。さらにレセプトデータも東大の小生の研究室で、6年分を格納したシステムを構築しています。このレセプトデータは我々が独自に内閣府最先端研究開発支援プログラム(FIRST)において開発しましたデータベース技術を利用しています。データベースの容量は既に2000億レコードに達しました。これほどの膨大なデータでありながら、検索処理は概ね1分以内に終了します。
とんでもないスケールのデータを、とてつもない速さで検索できるわけですが、ビッグデータに関して私は「Excelでは開けない」と定義しました。
レセプトデータは単年度で約400億レコードになります。Excelで扱えるのは、だいたい5000万レコードですからね。医師の先生方にデータを活用してもらうために、我々のようなデータベース研究者がお役に立てればと考えています。
21.3.22NEW
21.3.8
21.2.22
21.2.8
21.1.26